On most, if not all websites, there will be a need for a way to redirect users to other areas on the site after an action is performed.
If a user clicks on a link which redirects them to a login page, they will expect to be sent back to the page they were previously on.
One technique is to store this URL as a session variable, however, there are times when this is not practical, so the URL must be passed in the request. This method is perfect for any malicious users who wish to perform a phishing attack - the bad URL is hidden behind the legitimate one.
There are many methods to allow only specific values - encrypting the value (which in my opinion is over-kill), using an ID to map it against allowed values, or using a MAC. The simpliest is to check the URL that has been given, and ensure it matches our domain, if not, throw an error or ignore the value.
This is the approach employed on a lot of sites, Google being a good example, and Etsy being another. This post was spurred on by finding a loop-hole in the way Etsy checks the URL. They allow two types - either an absolute path (http://www.etsy.com/sell), or relative (/sell). The benefit of allowing relative is that providing that the URL starts with a slash, and that the value is escaped, we don’t care what’s in it - it will always resolve relative to http://www.etsy.com.
An Example
The variable from_page is (presumably) checked against a regex, and if the value doesn’t match, it’s reset.
However, the value isn’t checked for two leading slashes, so we can break out of the link being relative to the domain, and link to wherever we want!
Passing in a bad value
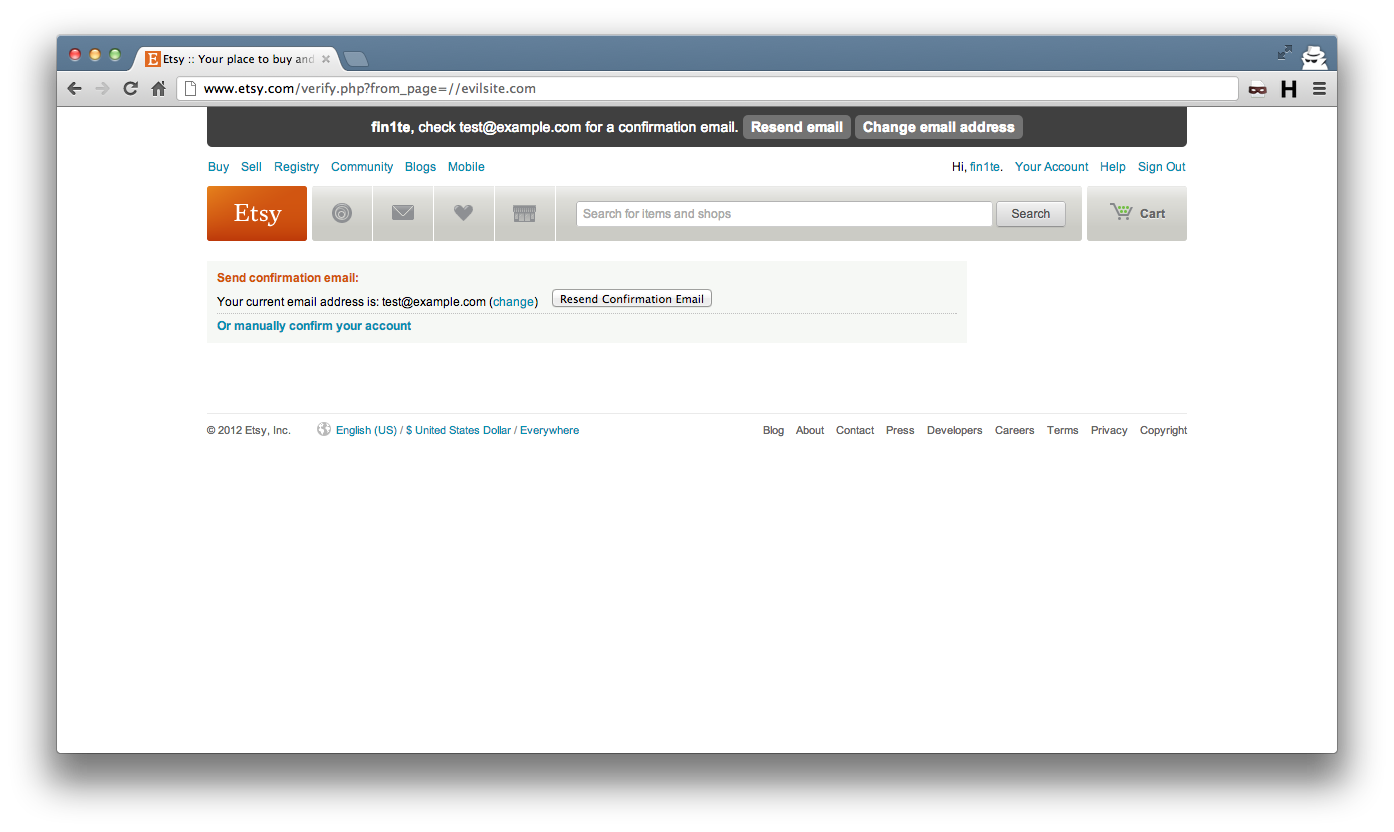
A link asking the user to continue is then displayed.
The resulting link, before the fix
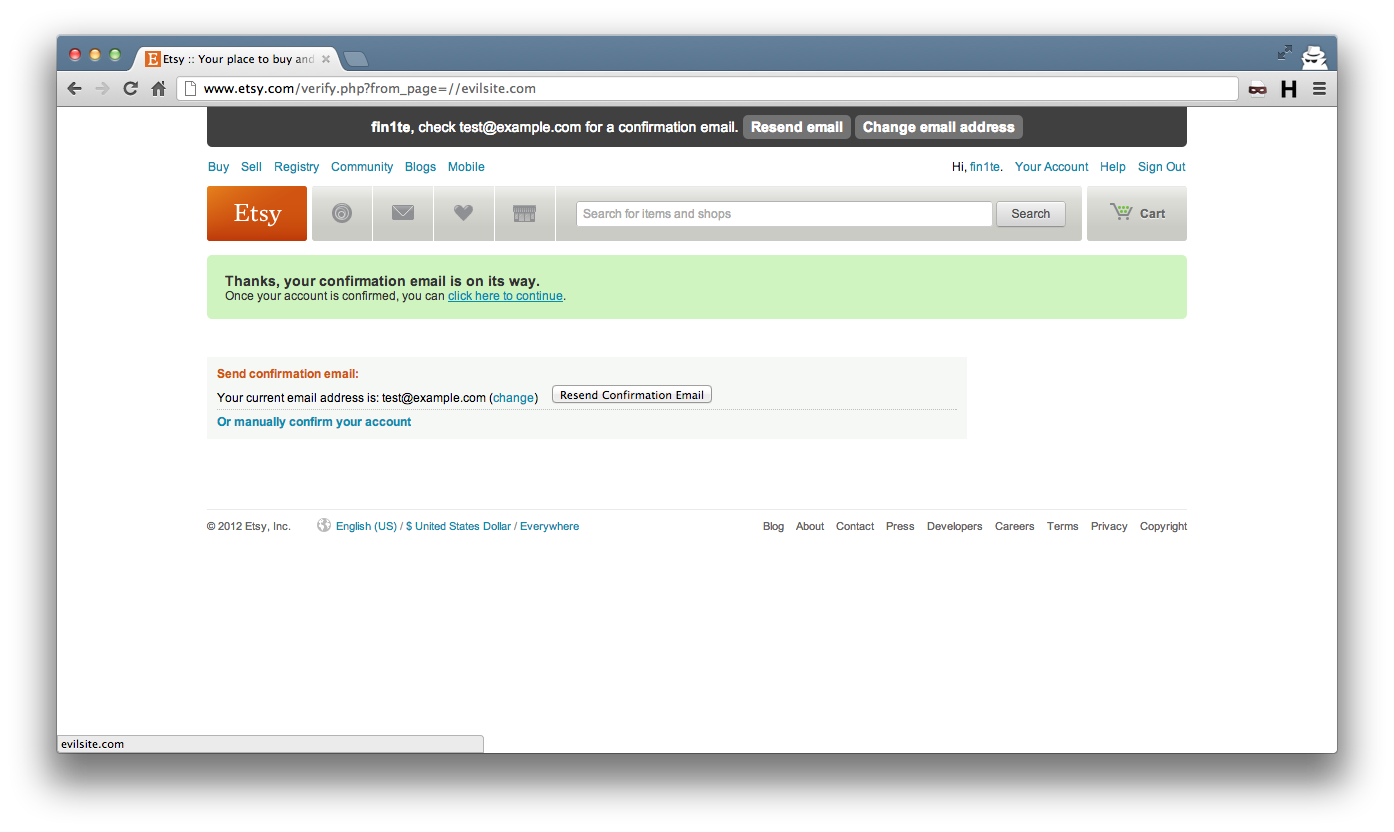
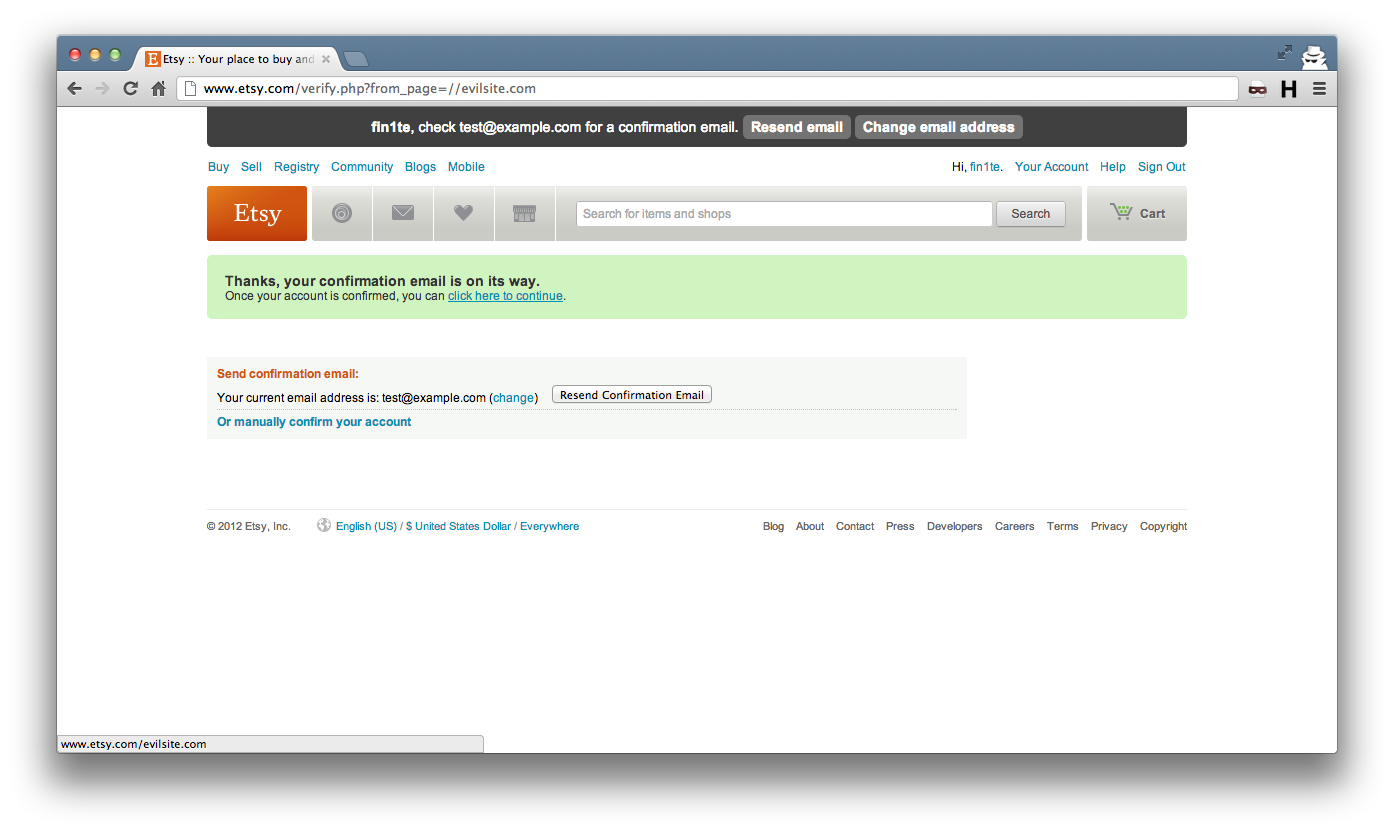
Etsy (very quickly, might I add) fixed this by removing any extra slashes at the start of the string.
The resulting link, after the fix
If our domain is example.com, we can use the following regex to ensure we only allow redirects to our sites.
<?php
$domain = 'example.com';
$regex = '/^(((http(s)?:)?\/\/' . preg_quote($domain)
. '($|\/))'
. '|(\/[^\/]))/';
//true
var_dump(preg_match($regex, 'http://example.com'));
//false
var_dump(preg_match($regex, 'http://example.com.evilsite.com'));
//true
var_dump(preg_match($regex, '//example.com'));
//false
var_dump(preg_match($regex, '//evilsite.com'));
//true
var_dump(preg_match($regex, '/home'));Line 2 we check for absolute URLs, or URLs with a relative protocol, that match our own domain.
Line 3 we make sure that the string either ends, or has a slash, to prevent attacks a la TimThumb.
Line 4 we check for relative URLs, that have only one leading slash.
For sites with multiple sub-domains, the regex is left as an exercise to the reader.