
A couple weeks ago I had my last day on Facebook’s Product Security team. A bittersweet moment, but one which marks a “new chapter” in my life…

I’ve spent just over 4 years working on “the other side” of bug bounties, but it’s also been 4 years since I last blogged, so I wanted to share some of my learnings as to how it was going from hacking on programs to being a security engineer.
I also wanted to share a bit about the journey I took. This is one of the first times I’ve been able to fully reflect (in a kinda long, rambly way), so writing this down was always going to be fun.
“Old-School” Bug Bounty
Without sounding like an old-school, grey-beard hacker (I’m not that old), the landscape really has changed over the ~8 years I’ve been following, and been a part of, the bug bounty community.
“Back in the day” you mainly had a choice of Google, Mozilla, Facebook and PayPal to hack on.
I have fond memories of having a Google alert setup for the words “bug bounty” and “vulnerability disclosure program”, just so that I could find any new program to hack on. There was also Bugcrowd’s infamous “The List”, which I’d consult.
Aside from the limited amount of programs, the tools and techniques used to find bugs on these various sites was wildly different than it is now.
Believe it or not, even the generic, “Paste an XSS payload into a search box”, bug taught in various old tutorials was a valid finding on large programs.
Now, it seems like a lot of the effort put in to finding bugs is in the context of recon - finding assets and end-points which could be pretty green and untouched, increasing the likelihood of finding a high paying bug. This is not necessarily a bad thing, it just means that it’s more important than ever for new-comers to understand WebAppSec techniques and the various recon tooling.
(As a side note, the one program I know of which doesn’t require heavy recon is Facebook, given that it’s a single, huge domain, but I may be bias promoting that particular program…)
First Reward
Anyway, digging through my bug bounty folder, I managed to find the first valid bug I found, which was a CSRF issue within PayPal. This was nearly 8 years ago, but it’s what got me hooked on something (relatively) new at the time - getting paid to find bugs.
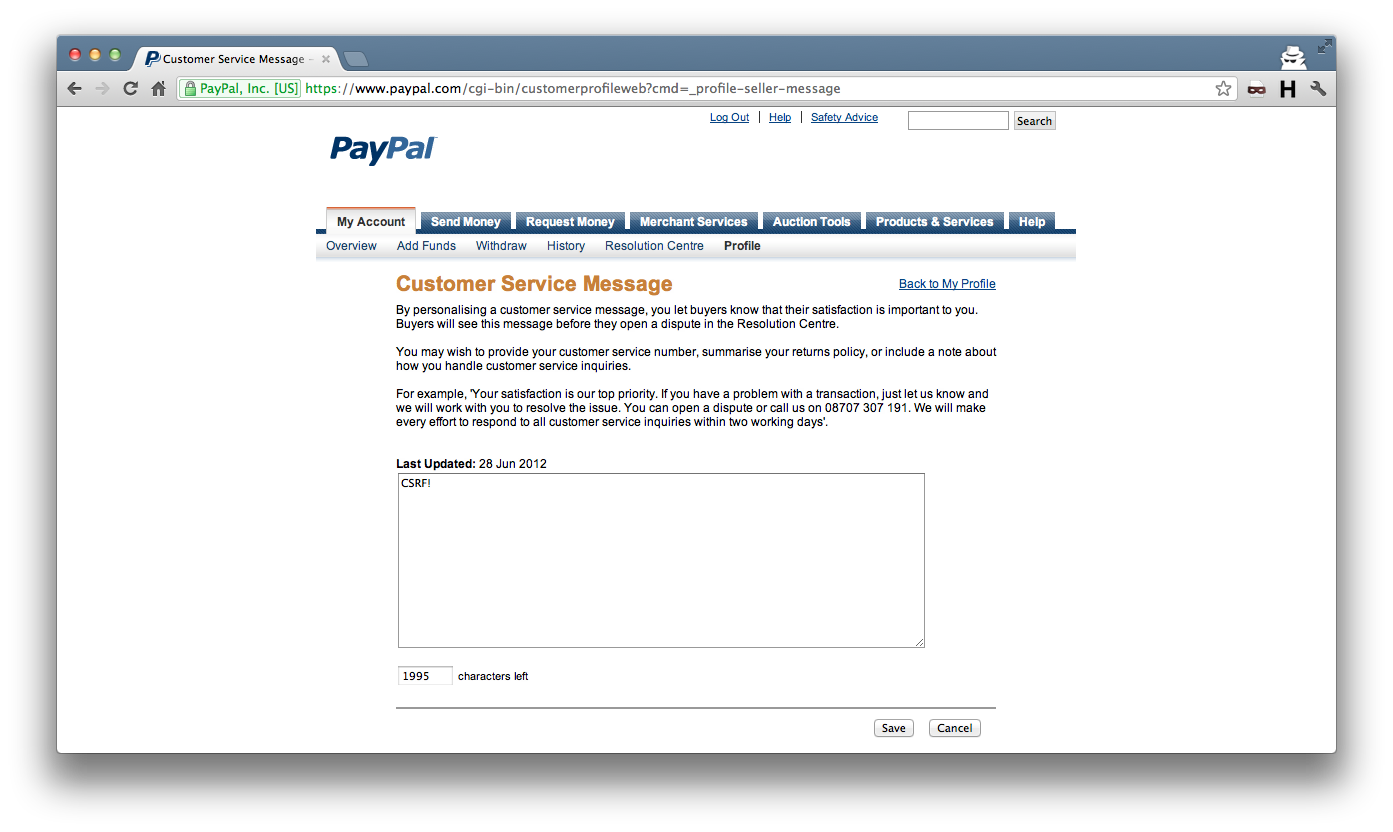
I’d sent in a few bugs prior to this, both to PayPal and Facebook, but receiving a “you’ve found an eligible issue” email felt great, despite the finding being pretty low-risk.
Ramping Up
From this point, I knew I needed to do two things:
- Learn as much as I could from other, more established researchers to understand their techniques for finding bugs (and the common patterns seen across a program)
- Find as many bugs as possible - in hindsight, this is not the best idea (as most programs value quality over quantity), but while I was starting out, it helped me get an idea of validity, and the non-technical aspects of writing reports etc
I also started blogging about my findings. The reason behind this was that I wanted to share some info back to the community that I’d learnt so much from. The other reason (which, IMO, is also a common reason) was that I could leverage these public blog posts into a job offer within the security industry. My background at the time was as a web developer, with no university degree or qualifications.
So from here, I hunted and hunted and hunted. The Yahoo program launched at some point in 2013 and it was so fun. Got some great findings and responses, including the following email I recently found buried in a screenshot folder somewhere.

Once they started paying their findings out via HackerOne, I had the (brief) enjoyment of being “The Top Hacker™”. That too was buried in a screenshot folder.
Around the same time, I started spending more and more time exclusively on the Facebook program.
This is a trend I still see today - as you hack more and more on the same program, you start to get a sense for how the code is written (despite black-boxing it), for when new code is deployed (despite not having access to the CI infra), and for when a mistake may have been made (which is when you turn that “spidey sense” into a valid submission).
Facebook Bug Bounty
The Facebook Bug Bounty program is where I spent the majority of my free time. I never made #1 on their leaderboard (always #2…), but I found some fun bugs and wrote up some interesting posts.
Over time I got to really understand the code behind www, despite never having seen it. The majority of findings are what would be called IDORs, although “bypassing read/write privacy” is a nicer term IMO.
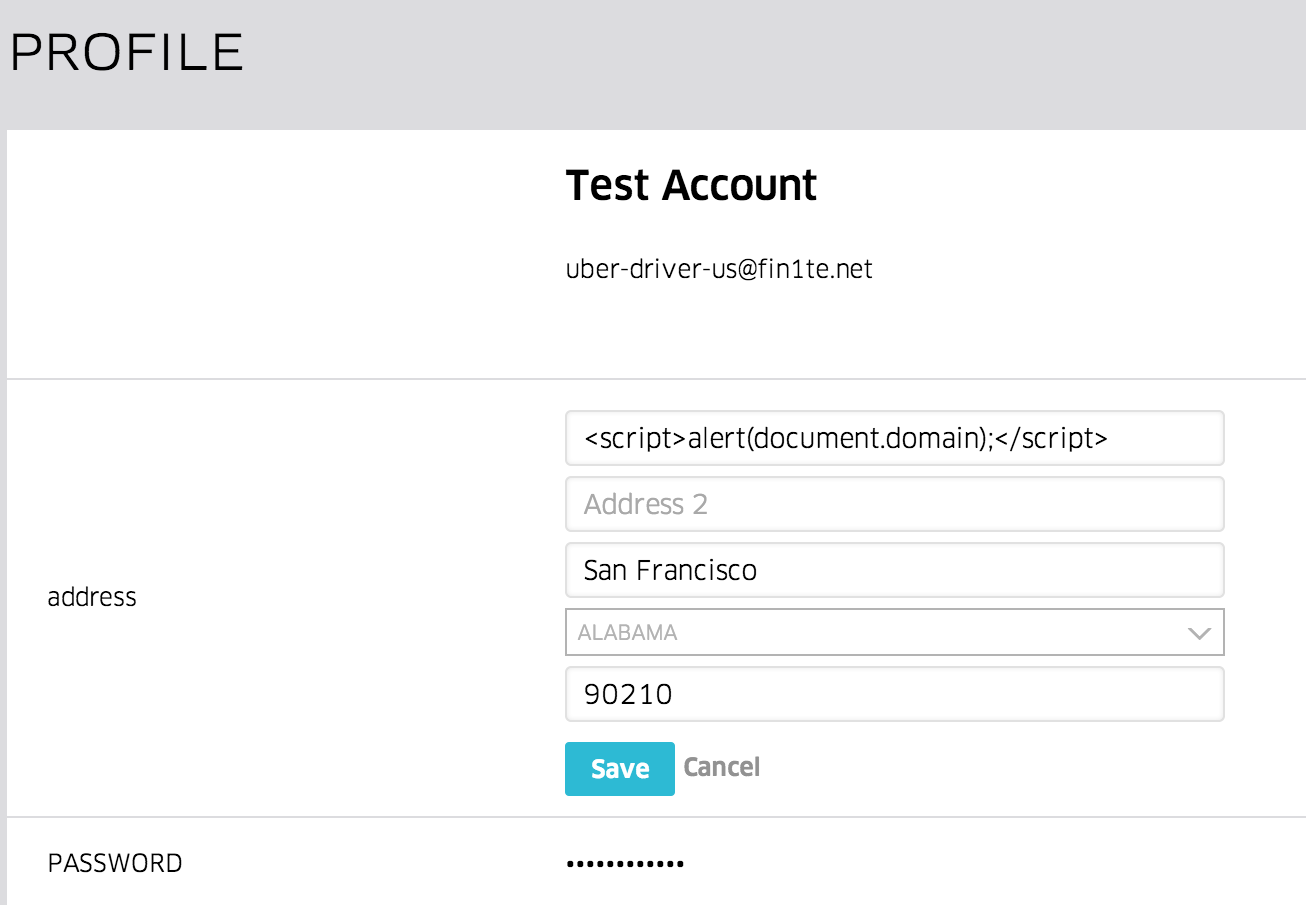
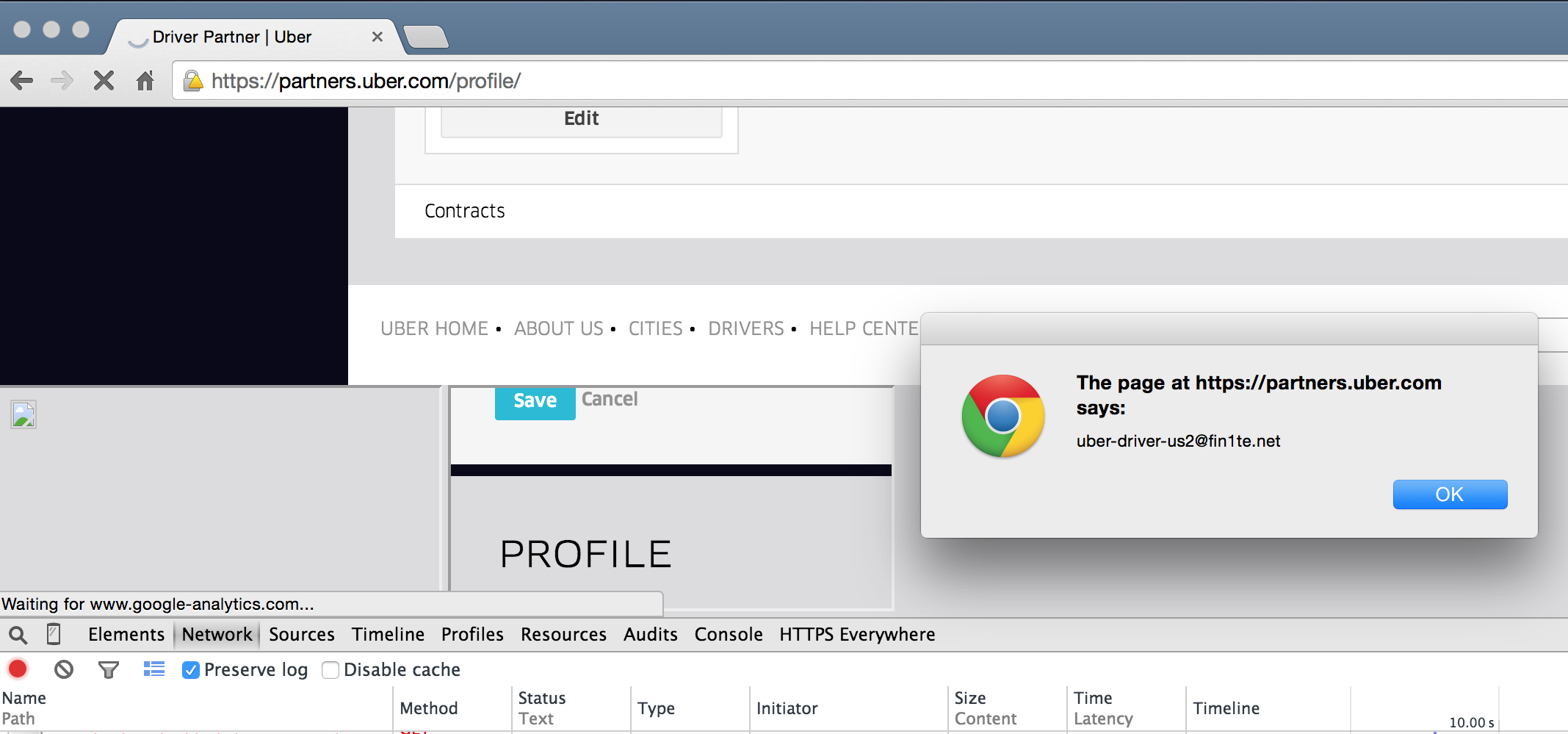
My biggest finding came when I found a way of accessing anyone’s account. This bug was one of the most simple, generic IDORs you could think of (change “profile_id” to someone else’s user ID…), but as with most programs, Facebook pays based on impact not on complexity.
For this bug, and others, they issued me one of the coveted Whitehat Debit Cards. It was fun (read: slightly annoying) having credit card receipts issued to Mr. Bounty.

Understandably, these aren’t used anymore as loading up and sending out thousands of cards per year would be too much, but back then the card itself was worth (to me, in terms of sentimental value) almost as much as the dollar reward.
After a few years of hacking Facebook spun up a ProdSec team in London, which was perfect as I’m based in the UK and didn’t want to leave to go to America.
I got the opportunity to interview for the role of Product Security Engineer, went to the office, did the interview…
Joining Facebook
…and failed. It sucked - joining Facebook was one of the end-goals of me spending so much time hacking on their program. But the reason I’m mentioning this (likely for the first time) is that in terms of a career, going back and having to re-learn some areas that you’re not 100% at isn’t a huge deal. I re-interviewed a while later and then joined in April 2016.
My first day was such a surreal experience. For years I knew the website inside and out, but finally I got a laptop with a check-out of the codebase.
_Spoiler: this post doesn’t contain any NDA-breaching info that will help you find bugs in Facebook. If you really want access to the secret codebase, click here_
I went through the usual bootcamp process that Facebook has, and finally joined the team to start looking for bugs and suggesting improvements to various product teams. This was when I made the (virtual) switch from being a “hunter” to an “engineer”.
“Everything is a P0”
A mindset that I needed to shift out of when joining Facebook was a common one that a lot of researchers have, and that’s that “every finding is a P0, you must fix this now, if you don’t the world will end and society will collapse”.
Now, there could be the odd bug where this is the case, but most of the time when working with a product team you need to understand trade-offs, and come up with solutions that are fair to other areas other than security.
You could be the most l33t researcher, dropping 0-days and absolutely crushing it, but if you can’t articulate risk to a non security engineer, then it’s not going to work out.
Running a Program
Given that my background is in bug bounties, it made sense for me to start working on Facebook’s own program. This too needed a bit of a mindset switch - I’d never triaged a report before, never looked for a root cause (other than in client-side JS), nor sat in on a payout meeting to discuss reward amounts.
But one thing that I could bring to the program was the empathy aspect, given that I’d been on the receiving end of messages and updates from a bug bounty program many times (one thing to note here is that this wasn’t a unique skill - at the time, and even more so now, some of the engineers working on Whitehat had bug bounty experience).
Researcher Engagement
One part of my role at Facebook that I kinda “accidentally” fell in to was giving presentations to researchers about our team, and the Whitehat program. It started off as something that I wasn’t sure I wanted to do - public speaking was a pretty big fear of mine, but I had an awesome manager who helped me overcome this fear.
But, after giving my first external presentation at Nullcon in 2017, I realised this was something I actually really enjoyed. Being able to share some “inside tips” on how people could succeed in the world of bug bounties was rewarding.
These presentations, and focus groups run with researchers, allowed me to understand the pain points and help ensure that researchers were enjoying their experience with the program.
In fact, this will be probably the biggest thing I’ll miss from Whitehat.
Finding Bugs as an Engineer
Whilst I was at Facebook, I did have the chance to find bugs in other programs, but my throughput went down massively. Prior to my start date, I was hunting most days and finding valid bugs in most of those sessions. However, after joining, these were the only months I hacked during (and some of these only ended up with one or two valids):
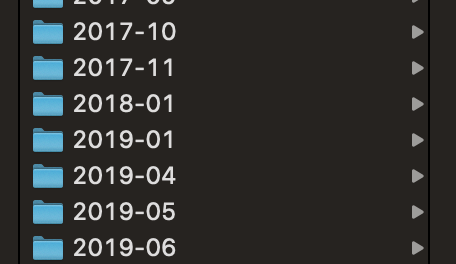
Given that my day was full up with engineering work, investigating security bugs, etc, I took the decision to ensure that my free time was full of non-work related things (for more info, you should really read NathOnSecurity’s post regarding Bug Bounties and Mental Health).
But for the few times I was hunting, the technical and non-technical skills I was learning and using from helping run the Whitehat program, and from security reviews for teams, helped greatly:
Visualing Code
After reviewing enough code (which believe me, I did…), you start to be able to visualise how a request is being handled. This is usually regardless of the application, or language it’s written in, given that in most cases it’ll be roughly similar.
In terms of bug bounty, this helped a lot. I could look at an end-point, guesstimate what could be happening to the parameters I’d passed in before the HTTP response is sent. Now, given that I’d seen some of the common mistakes Software Engineers had made over the years with handling user-provided data, you can then assume that other engineering teams at other companies could be making similar mistakes, and therefore find bugs that way.
The great thing about this is that you don’t need to join a tech company to learn this skill. Chose a random web app open source project on GitHub and take a look through some of the previous security issues they’ve had. You’ll see real world mistakes, from real world engineers, and can then start to visualise these mistakes when black-box testing a bug bounty property.
Empathy
As I mentioned above, empathy was a key aspect to the 4 years at Facebook, both inside and outside of work.
As a researcher, sending in a submission, you want to have a reply within minutes, a fix within hours, and a $$$$ payout within a day. In an ideal world, that’d be the case, but it doesn’t work like that.
When sending in bugs, you have to understand the huge amount of work that could be going on behind the scenes.
For example, a bug may look like a simple reflected XSS which just needs a variable wrapped in htmlspecialchars for the submission to be resolved (pro-tip: please don’t actually fix XSS this way…), but in-fact it’s a systemic issue in a core library used by a ton of random properties.
In addition, consider the fact that it may have been exploited, so now various other teams have to do IR, or legal teams need to be involved before any replies can be sent to a researcher.
Now, that’s not to excuse the cases where a submission gets lost in the ether, or where the program simply doesn’t care about security issues (I’m purposely leaving out 30/90/120 day disclosure deadlines etc out of this post so that I don’t start a Twitter storm…), but more often than not, for a reputable program, bugs are being fixed but can take a lot longer than it seems.
Reward Amounts
Similar to the empathy aspect of the (potential) long waits for bugs to be fixed, one other area that I got to learn a lot about was reward amounts. The main thing to mention here (and of course there are caveats, but this should be the same for any reputable program) is that programs aren’t trying to cheat you out of a reward. No (again, reputable) program is trying to shave off $500 off of your reward just to “save money”.
One of the ways that can help alleviate these concerns is by publishing reward amounts of various bug types (or even examples of amounts for previous specific findings), but even this can cause drama - if the bounty table says “SSRF - $10,000”, but you only get paid $5,000, then you’ve been cheated, right?
Well, not exactly, since more often than not you need to consider the following:
- Do you need to be authenticated to perform the SSRF, and if so, what type of account do you need (one requiring high-privs is going to be harder to exploit)?
- Is the host which is vulnerable to SSRF firewalled/in a DMZ?
- Can you extract data or only blindly hit end-points with a GET?
And so on….
Programs can help you in these cases where you feel there is a discrepancy by explaining the mitigating factors (or in the case you got more than $10,000, by explaining the compounding factors), but again, (most) programs aren’t lowering the amounts just to “save money”.
The Future
Soon I’ll be starting a new role, one which will likely see me slightly more removed from the bug bounty world, but I’ll keeping a close on eye on the ever changing techniques and novel findings 👀.
In terms of the future of bug bounties, who knows what will be the new norm over the next 4 years, but regardless I’m sure it will benefit both sides of the community.
I may also dump a few of my older findings from over the past few years on this blog…
Thank You
Finally, one thing I neglected over the years was to give specific “thank-you” to all of the various researchers who helped me be who I am today, either directly or indirectly.
The OG 2012/2013 Facebook Hunters (Egor, Nir, Neal, Charlie B) who blogged are a main reason I am where I am today. Then the researchers who were hacking (and still are) at the same time as me, Josip & phwd (too many fun times at DEFCON together…), Anand, Pranav, Dmitry, Youssef, and many others.
Theres also the hunters who made me feel welcome at my first, and all the future DEFCONs - Bitquark, Jhaddix, Nahamsec, and plenty more.
And then finally, the people who still blow my mind when I read their posts - Ngalog for taking over the #1 spot on Uber from me, Shubs for his crazy recon skills, Frans for the sick presentations I’ve seen at our events, and so on…










{kind=link}
{kind=link}
{kind=link}