I haven’t blogged for quite some time, so I thought it was worth re-launching with an interesting, albeit simple, high-impact bug.
Periscope is an iOS/Android app, owned by Twitter, used for live streaming. To manage the millions of users, a web-based administation panel is used, accessible at admin.periscope.tv.
When you browse to the site, all requests are redirected to /auth?redirect=/ (since we don’t have a valid session), which in turn redirects to Google for authentication.
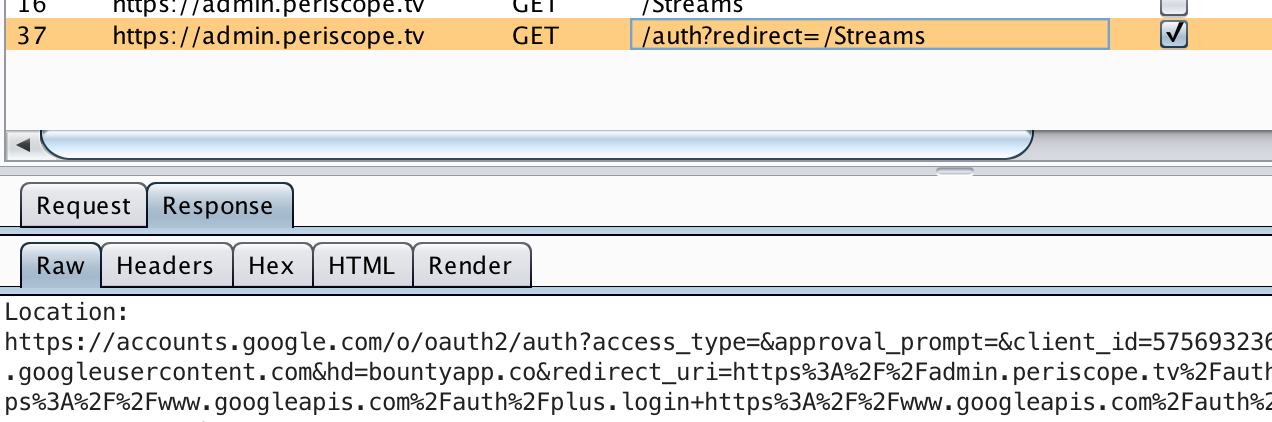
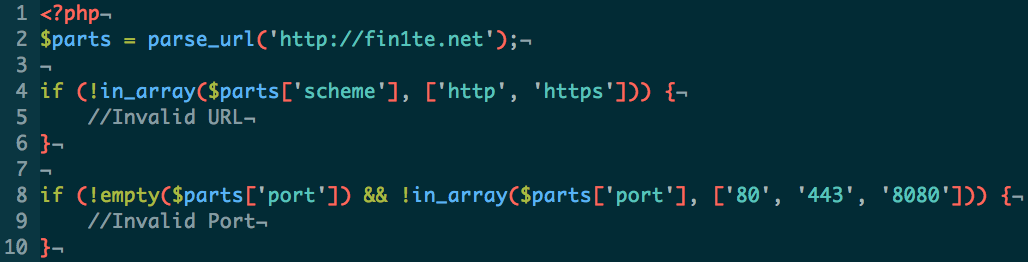
The redirected URL, shown below, contains various parameters, but the most interesting one is hd. This is used to restrict logins to a specific domain, in this case bountyapp.co.
https://accounts.google.com/o/oauth2/auth?access_type=
&approval_prompt=
&client_id=57569323683-c0hvkac6m15h3u3l53u89vpquvjiu8sb.apps.googleusercontent.com
&hd=bountyapp.co
&redirect_uri=https%3A%2F%2Fadmin.periscope.tv%2Fauth%2Fcallback
&response_type=code
&scope=https%3A%2F%2Fwww.googleapis.com%2Fauth%2Fplus.login+https%3A%2F%2Fwww.googleapis.com%2Fauth%2Fuserinfo.profile
&state=%2FStreams
If we try and login with an account such as [email protected], we’re redirected back to the account selection page, and if we try again we get redirected back to the same place, and so on.
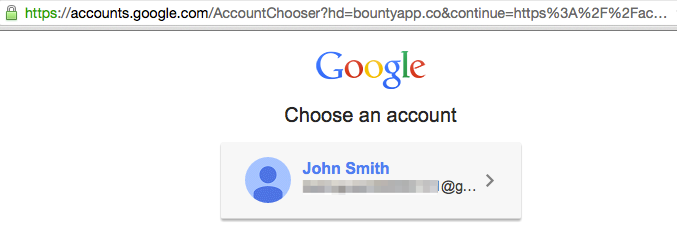
However, we can simply remove this parameter. There’s no signature in the URL to prevent us from making modifications, and as indicated in the documentation, the onus is on the application to validate the returned token.
This gives us the following login URL (you may also notice I’ve removed the Google+ scope, this is purely because my test account isn’t signed up for it):
https://accounts.google.com/o/oauth2/auth?access_type=
&approval_prompt=
&client_id=57569323683-c0hvkac6m15h3u3l53u89vpquvjiu8sb.apps.googleusercontent.com
&redirect_uri=https%3A%2F%2Fadmin.periscope.tv%2Fauth%2Fcallback
&response_type=code
&scope=https%3A%2F%2Fwww.googleapis.com%2Fauth%2Fuserinfo.profile
&state=%2FStreams
Browsing to this new URL prompts us to authorise the application.
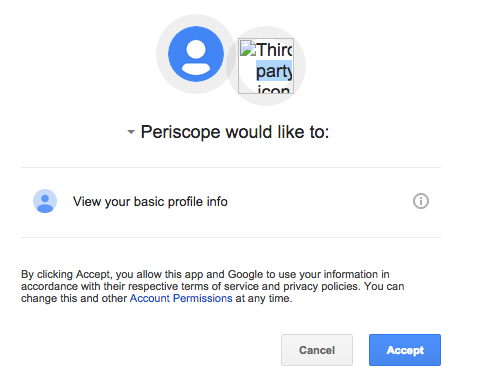
After clicking “Accept”, a redirect is issused back to the administation panel, with our code as a parameter.
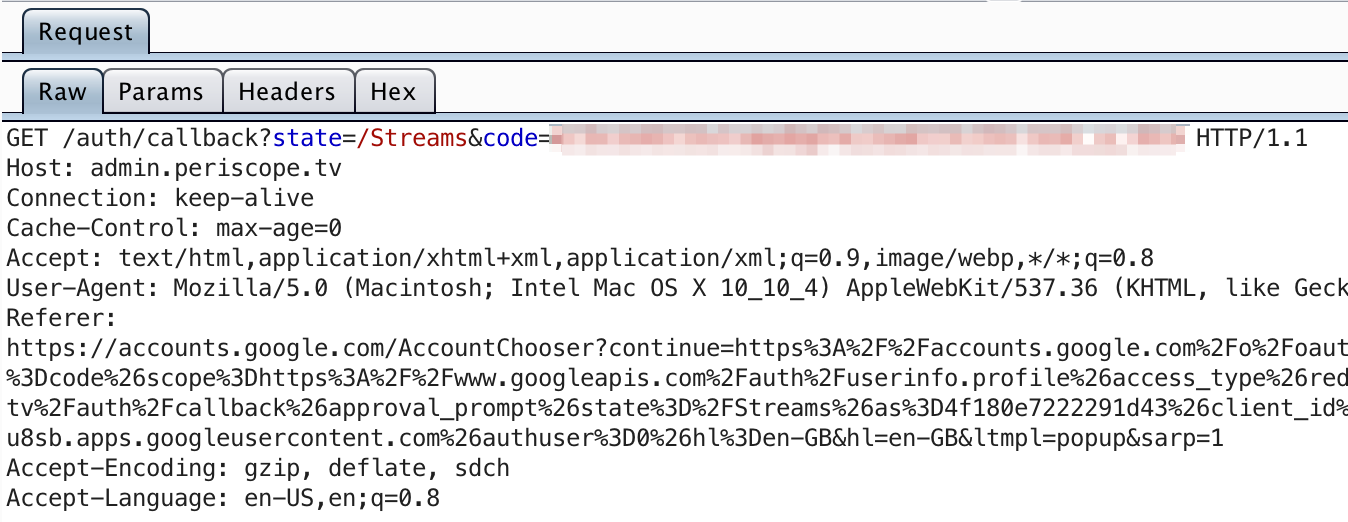
This is where the application should then exchange the code for an access token, and validate the returned user ID against either a whitelist, or at the very least verify that the domain is bountyapp.co.
But, in this case, the assumption is made that if you managed to login, you are an employee with an @bountyapp.co email.
The requested userinfo.profile permission doesn’t contain the user’s email address, so the application can’t validate it if it tried.
This then presents us with the admin panel.
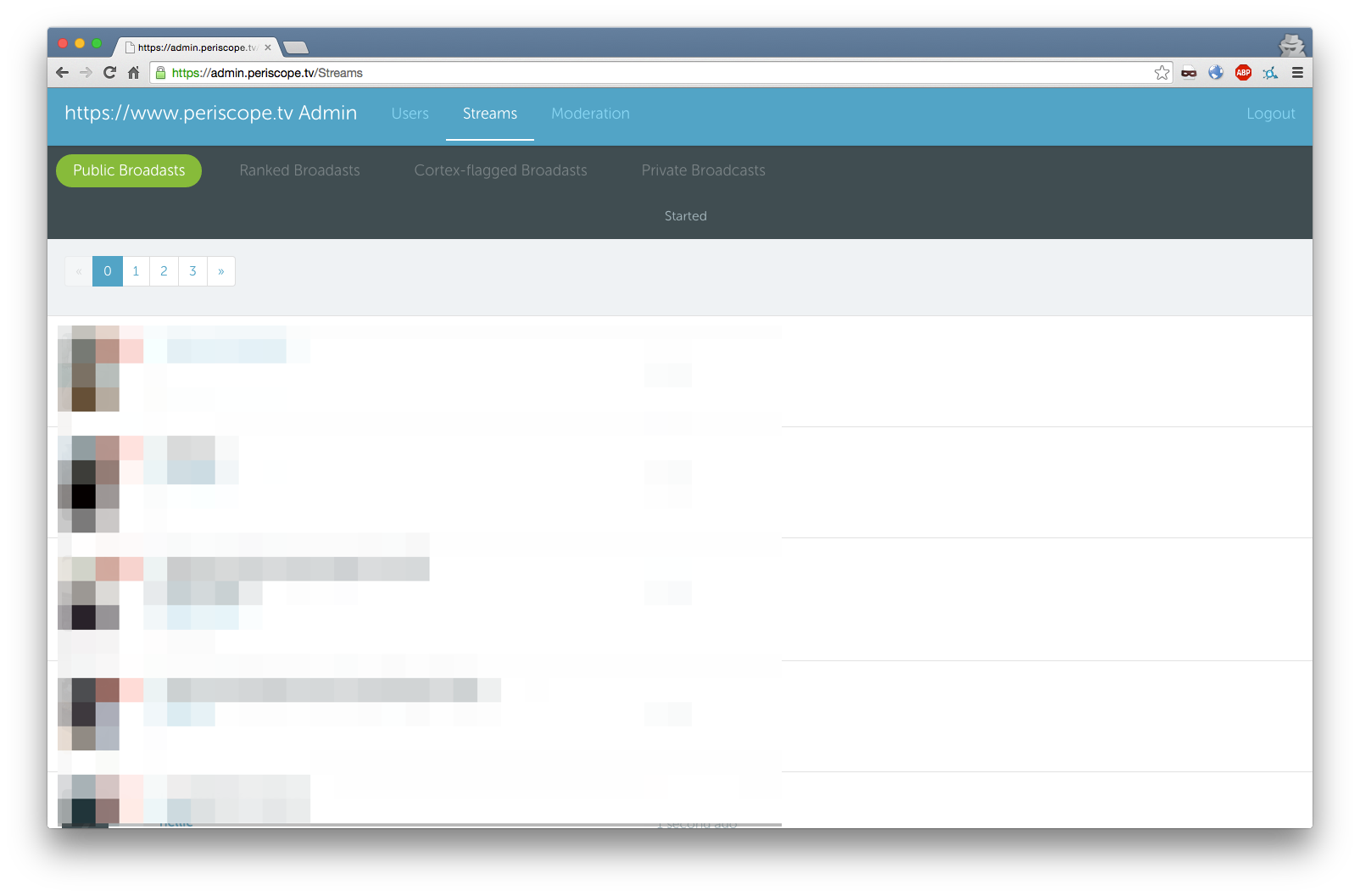
From here we can now manage various aspects of Periscope, including users and streams.
Fix
Twitter fixed this by making two changes. The first is to request an additional permission:
https://www.googleapis.com/auth/userinfo.email
The second is to correctly validate the user on callback.
Now, the application returns a 401 when trying to authenticate with an invalid user:
HTTP/1.1 401 Unauthorized
Content-Type: text/html; charset=utf-8
Location: /Login
Strict-Transport-Security: max-age=31536000; preload
X-Content-Type-Options: nosniff
X-Frame-Options: DENY
X-Xss-Protection: 1; mode=block
Content-Length: 36
<href="/Login">Unauthorized</a>.