tl;dr: ISPs, please reduce your cookie scope.
Everyone now knows that hosting user generated content on a sub-domain is bad. Attacks have been demonstrated on sites such as GitHub, and it’s why Google uses googleusercontent.com.
But what if you’re an ISP. You might not host any user-content, however, you probably assign customers an IP which has Reverse DNS set. You’ll probably see hostnames like 1-1-1-1-ip-static.hfc.comcastbusiness.net or 2.2.2.2.threembb.co.uk.
This isn’t really an issue. The issue is when the hostname assigned is a sub-domain of your own site. If you do this, along with cookies with loose domain scope (fairly common practice), and forward DNS (again, fairly common), then this combination can result in cookie stealing, and therefore account hijacking.
To pull this off, an attacker either needs to be a customer of the ISP they’re targeting, or have access to a machine of a customer (pretty easy with the use of botnets). A web server is then hosted on the connection, and referenced by the hostname assigned (as opposed to the IP).
Example
Rather than showing a real world example, I’d rather keep the companies names private, I’ve setup a proof-of-concept.
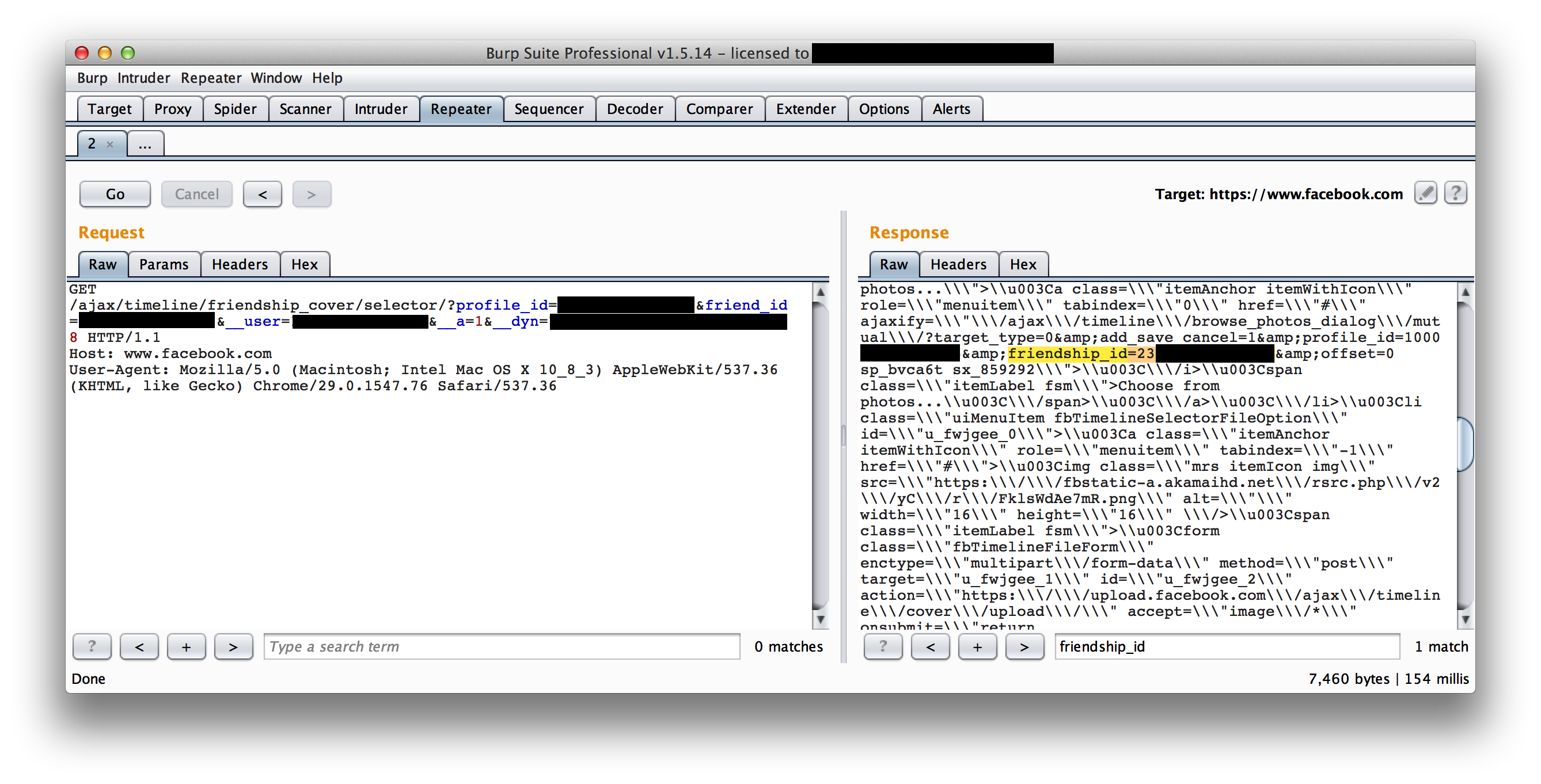
We have a fake ISP hosted on fin1te-dsl.com, which mimics an ISPs portal. Registering an account and logging in generates a session cookie (try it out).
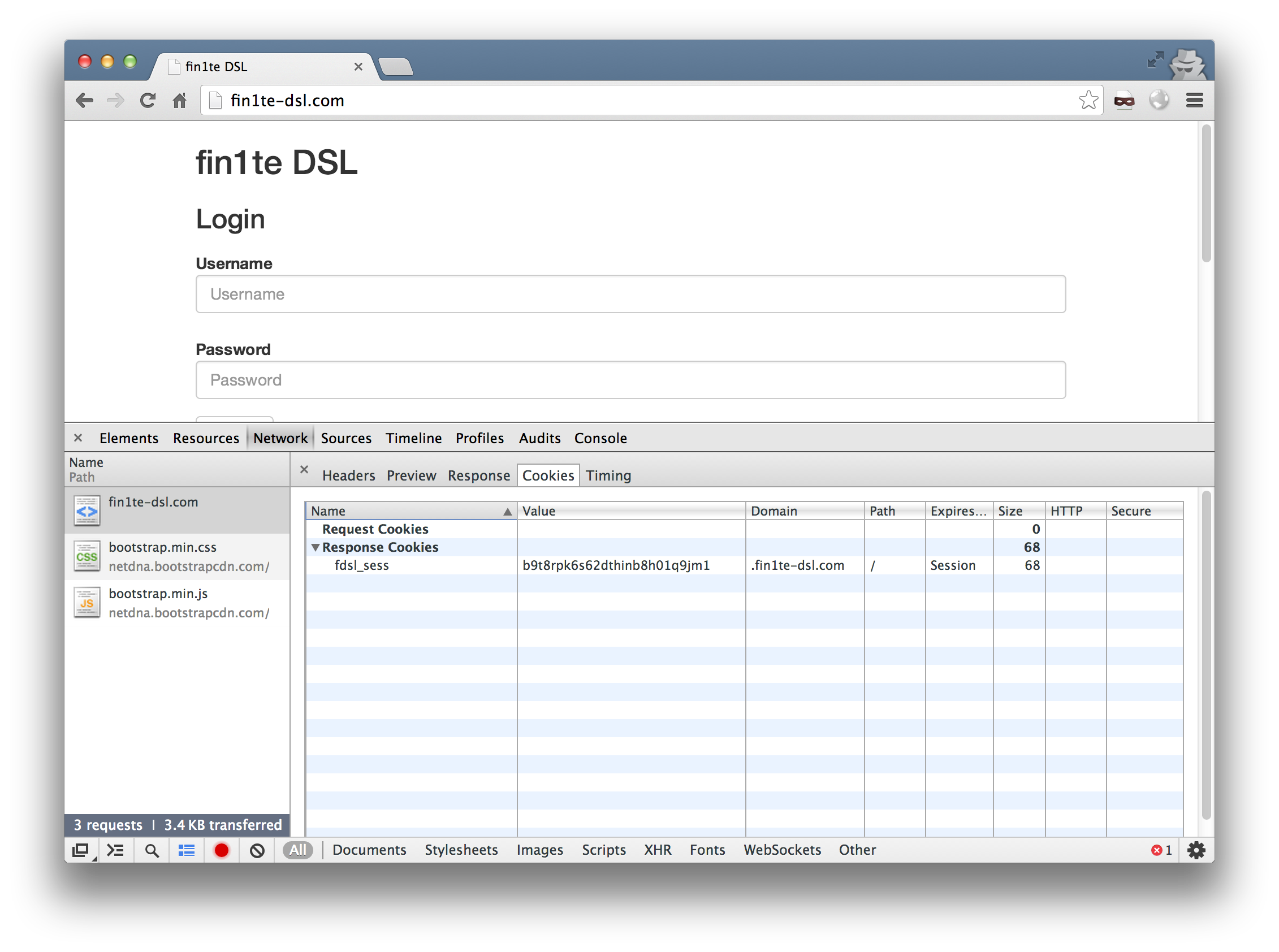
We also have a site (152-151-64-212.cust.dsl.fin1te-dsl.com) which in real life would be hosted on a users own connection. A page, 152-151-64-212.cust.dsl.fin1te-dsl.com/debug.php, is hosted to display the cookies back for debug purposes.
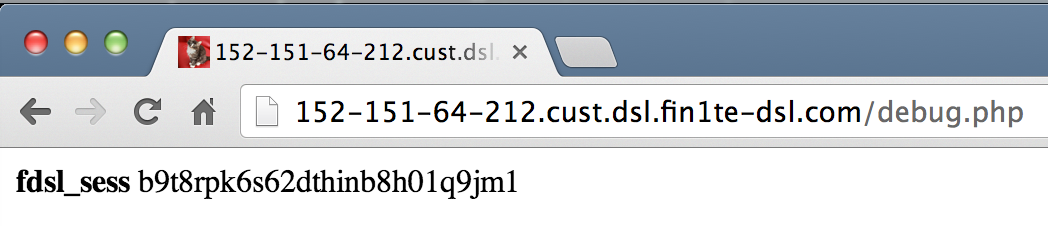
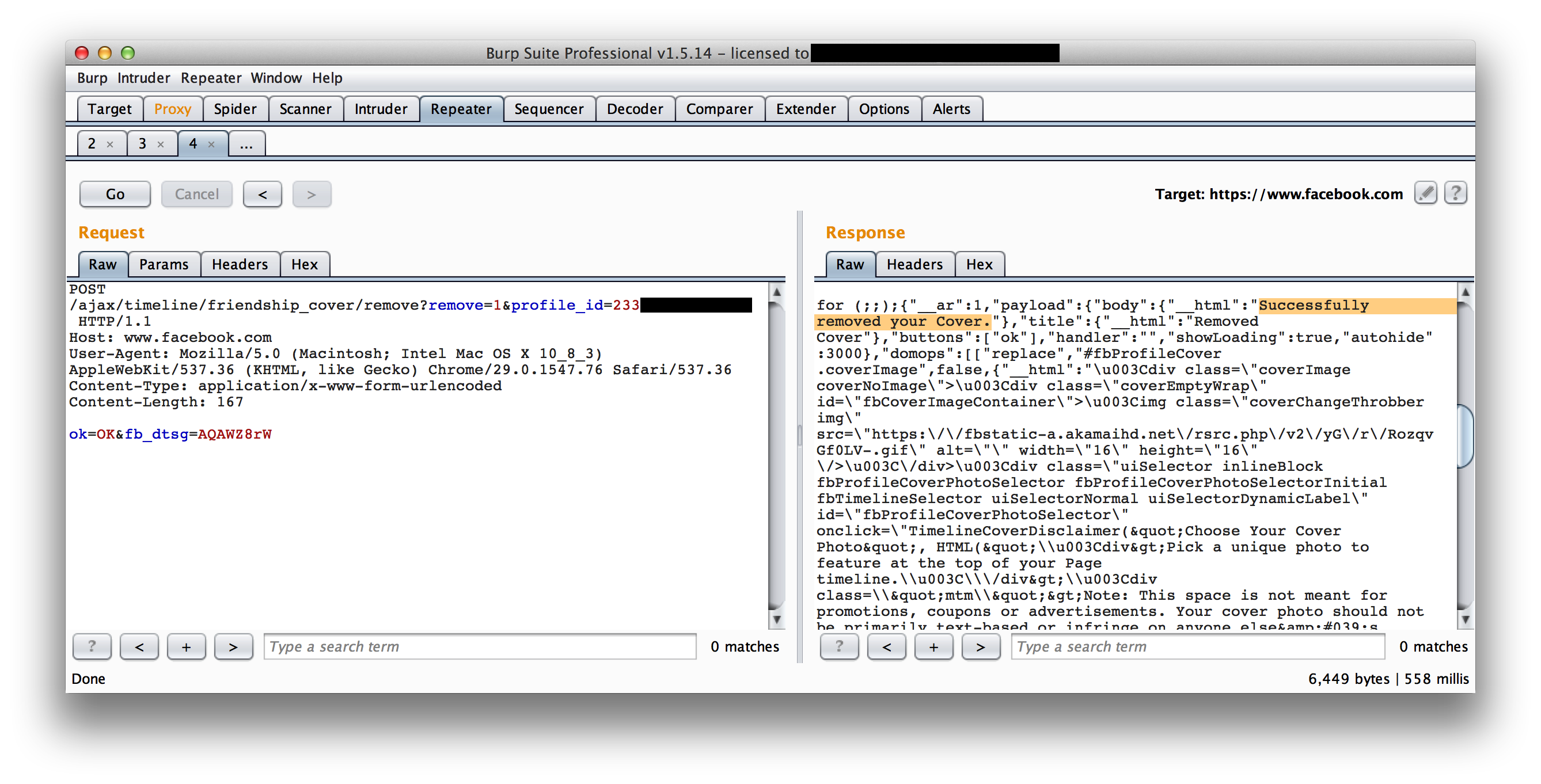
Now, we just need a user who has a session to submit a request to our own site and we can grab them. Since we’re accessing the cookies via the HTTP request and not via Javascript, we can write a quick stealer which sets a content-type of image/jpeg and embed the image on a page.
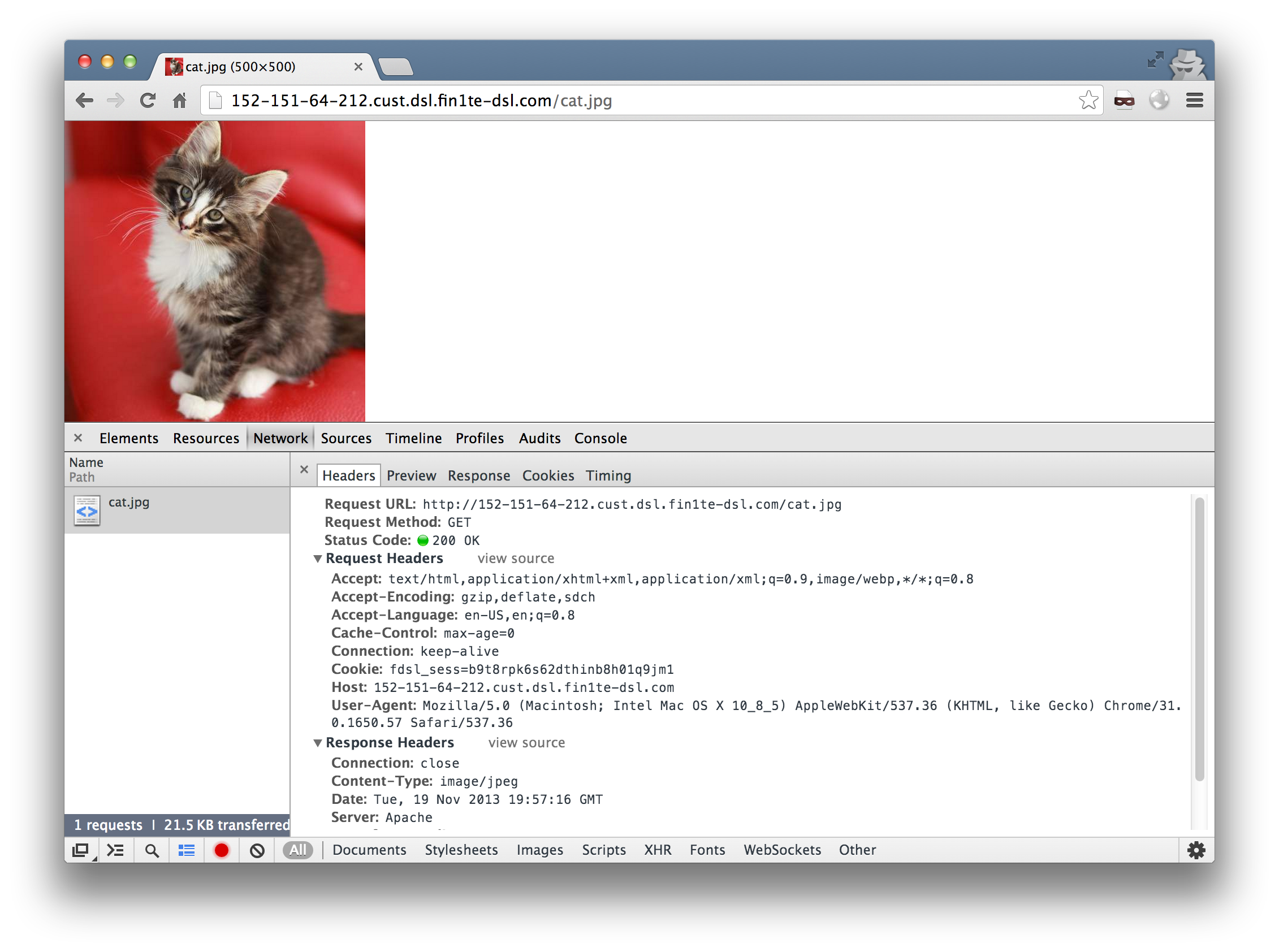
And the cookies show up in the logs.

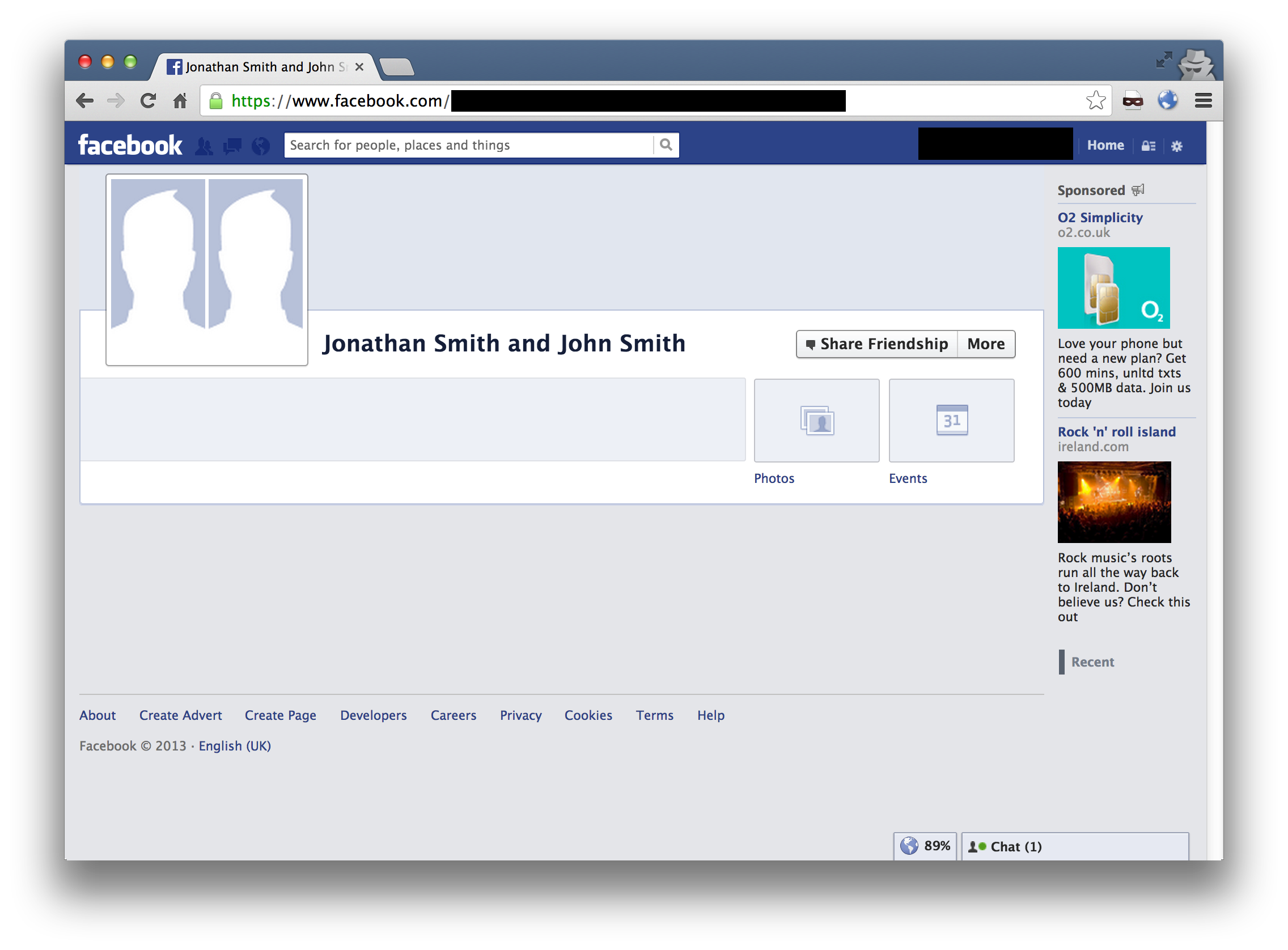
We just need to set our own cookie to this value and we’ve successfuly hijacked their session.
Out of the four major UK ISPs I tested, two were vulnerable (now patched). If you assume an equal market share (based on 2012 estimates), that’s approximately 10.5 million users who can be potentially targeted. Of course, they have to be logged in - but you can always embed the cookie stealer as an image on a support forum, for example.
Mitigation Techniques
We have three mitigation options. The first is to remove super cookies and restrict the scope to a single domain. This may be impractical if you separate content onto different sub-domains. The second is to disable forward DNS for customers. And the third is to change the hostname assigned to one which isn’t a sub-domain.
In addition, techniques such as pinning a session to an IP address will help to an extent. Unless you store a CSRF token in a cookie, in which case, we can just CSRF the user.
Source
If you want to browse the source code of the proof-of-concept, it’s available on Github.
Note
Since I didn’t have the time to test every single ISP in the world (just the UK ones) for the three requirements that make them vulnerable, I decided to send an email to security@ addresses at the top 25 ISPs - 20 of these bounced, and I received no reply from the other 5.
The two UK ones I originally contacted patched promptly and gave good updates, so kudos to you two.